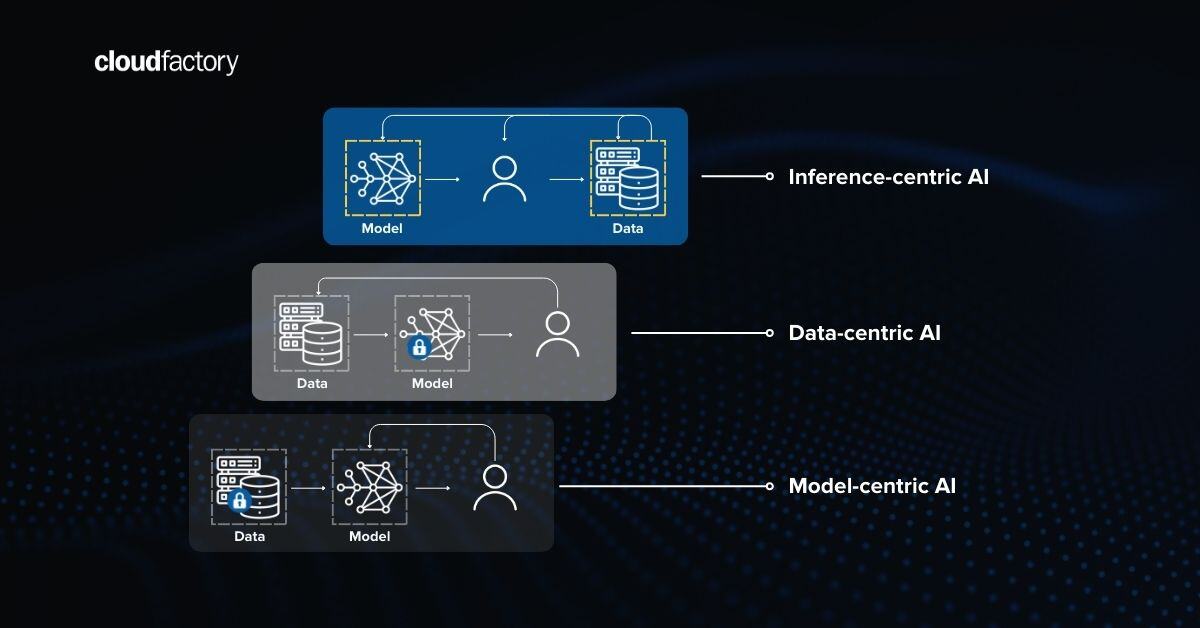
The evolution of Machine Learning (ML) has been marked by three distinct waves—model-centric, data-centric, and inference-centric—each with a unique focus and set of priorities. These waves reflect the field's progression as it adapts to new challenges and opportunities. Understanding these waves can provide insights into the past, present, and future of ML development and deployment.
At CloudFactory, we believe that inference-centric AI development is the next wave. Inference optimization unlocks AI's value by closing the gap between a model's current performance limits and desired outcomes. But what exactly does this mean? To fully grasp the concept, let's break down the key components of any AI solution.
Key components of an AI solution
On a high level, AI solutions can be divided into three main components: data, models, and processes.
Data is a crucial aspect of the Machine Learning (ML) pipeline. To effectively train a model, vast amounts of structured, labeled data are required and prepared for use in training batches. AI data can be considered as the “input” to the model, comprising images and annotations derived from data collection, curation, and annotation stages. The Model component represents the ML algorithm, which takes this data as input and is trained to solve specific problems, producing interpretable predictions.
The surrounding processes dictate how developers build a cohesive AI solution. They encompass all steps of the ML pipeline, including data gathering, data annotation, model training, and model monitoring. Each element integrates data, model aspects, and detailed process descriptions to create a seamless and efficient AI workflow.
So, which component drives more value for the final solution? Over time, the community's opinion has evolved, prompting the AI field to adapt accordingly.
While model-centric, data-centric, and inference-centric approaches in machine learning strive for production-ready accuracy, their methodologies vary.
Wave 1: Model-centric machine learning
The first decades of AI were purely model-centric, leading to remarkable growth and advancements in model-related fields. During this period, the primary focus was on developing and refining algorithms. Significant breakthroughs were achieved by proposing new neural network architectures such as AlexNet, ResNet, and ResNeXt and building features that enhanced model training, giving an edge in model-related processes.
Key characteristics of model-centric ML
- Algorithm innovation: Significant efforts were devoted to inventing and improving algorithms. Various backbones, such as neural networks, decision trees, and support vector machines, were developed and fine-tuned.
- Model performance: Emphasis was placed on achieving high accuracy and performance metrics. Researchers and practitioners competed to create models that could outperform others on benchmark datasets, such as the "Image Classification on ImageNet" competition, where performance steadily improved over time with the introduction of new architectures and techniques.
- Compute power: The rise of powerful computing hardware, such as GPUs, enabled more complex models and deeper neural networks, leading to breakthroughs in various fields, including image and speech recognition.
Impact of model-centric ML
Model-centric AI development doesn't mean that data and process components were ignored, but in practice, the model often overshadowed them, diverting most resources and focus. A paramount example of model-centric success is the AlexNet neural network architecture, which demonstrated the power of deep learning for image classification tasks.
Introduced in 2012, AlexNet utilized a deep convolutional neural network (CNN) with eight layers, significantly more profound than previous networks. It utilized GPUs for faster training on large real-world datasets like ImageNet, using techniques such as ReLU activations, dropout for regularization, and overlapping max-pooling.
AlexNet's victory in the ImageNet Large Scale Visual Recognition Challenge 2012 (ILSVRC), where it significantly outperformed other models, showcased the potential of deep learning models to handle complex, real-world data and achieve superior performance over traditional methods and, potentially, humans. This success sparked a renewed interest in deep learning and CNNs, marking a pivotal moment in the evolution of AI towards model-centricity.

The model-centric AI development approach doesn't mean an AI team should ignore the data and process components. The challenge is that the model often overshadows them in real life, diverting most resources and focus to itself, disrupting the ideal balance.
Shortcomings of model-centric ML
While driving significant advancements in algorithm development, the model-centric approach often overlooks the importance of high-quality, diverse data and robust processes. This leads to models that may perform well in controlled environments but struggle with real-world variability. Additionally, this approach can cause resource imbalances, where excessive focus on model refinement diverts attention from critical aspects like data curation, annotation, and model deployment.
Wave 2: Data-centric machine learning
As the limitations of model-centric approaches became apparent, the second wave of ML shifted focus to data, giving rise to data-centricity. The data-centric wave views the data component as the cornerstone of the solution. The philosophy behind this approach is that your model is only as good as the data it was trained on. Key aspects of good quality data include data distribution, class balance, high-quality annotations, meta-level labels, and labeling consistency.
Key characteristics of data-centric ML
- Data collection: Gathering vast amounts of data from various sources, including structured data, unstructured data, and real-time data streams.
- Data quality: Ensuring that data is clean, well-labeled, and representative of the problem domain. Techniques for data cleaning, preprocessing, and augmentation became crucial.
- Data engineering: Developing tools and platforms to efficiently manage and process large datasets. Data pipelines, ETL (Extract, Transform, Load) processes, and data lakes have become integral components of ML workflows.
Impact of data-centric ML
Data-centric AI development doesn't mean an AI team should ignore the model and process components. Its logic assumes that the data should be the primary focus when developing an AI solution. Compared to the model-centric approach, data-centric AI development is more focused on processes than technology. The only way for a team to get high-quality data (besides outsourcing) is by establishing robust human-in-the-loop data annotation, quality control, and data flywheel processes in-house. This shift in perspective brought a new generation of AI enthusiasts who were more practical and business-oriented, as establishing processes to build AI solutions does not necessarily require deep data science experience. This fresh breeze revitalized the community, which had started running out of steam with the model-centric marathon.

Data-centricity gained traction over model-centric narratives and became the next big wave in AI development. The new paradigm allowed for the addressing of new challenges and the development of new approaches.
To give a real-world example, Elon Musk’s Tesla started thriving with its autopilot and full self-driving capability right at the time when data-centricity found its stride. Over the years, Tesla’s technology has shared that these features rely heavily on data. Developers say the data is gathered from millions of miles driven by Tesla owners and used to train and refine Tesla’s AI algorithms to improve the performance and safety of their AI systems.
Shortcomings of data-centric ML
The initial excitement surrounding data-centric approaches is beginning to fade as challenges such as the increasing complexity and diversity of data sources emerge. Despite this, the evolution of the AI field continues, with the industry seeking new ideas and innovations to drive progress.
Wave 3: Inference-centric machine learning
The third wave of ML, inference-centric, focuses on deploying and operationalizing machine learning models. This wave addresses the challenges of making models work reliably and efficiently in real-world applications.
Key characteristics of inference-centric ML
- Deployment: Techniques for deploying models in various environments, from cloud servers to edge devices. This includes containerization, microservices, and serverless architectures.
- Scalability: Ensuring models can handle large-scale inference workloads. This involves optimizing models for speed and resource efficiency and using distributed computing.
- Monitoring and maintenance: Continuous monitoring of model performance in production to detect and address issues like drift, anomalies, and degradation. This includes implementing feedback loops for model updates and improvements.
- Explainability and trust: Providing interpretable and trustworthy predictions. Techniques for model explainability, fairness, and bias detection are essential for building user confidence and regulatory compliance.
Impact of inference-centric ML
At CloudFactory, we recognized the changing tide very early when our clients asked for streamlined development to accelerate inferencing and production deployment. In ML, inference refers to using a trained model to make predictions or decisions based on new unseen data. The inference-centric approach views the process component as the cornerstone of the AI solution, focusing on the real-world performance of models. This approach enhances the traditional ML lifecycle by optimizing inference measurements as a solution’s success metrics. It continuously integrates model- and data-centric techniques to fine-tune and improve AI solutions based on performance findings.
Inference-centric example process
- Identify the task and business case: Quickly develop or obtain a trained model for inferencing, overcoming any obstacles using a fine-tuned foundational model.
- Test the model: Evaluate its performance against unseen data in a staging environment to assess its applicability.
- Focus on inference: Analyze the model’s performance metrics on unseen data and make data-driven decisions to improve key metrics. For instance, critical edge cases can be addressed through the data flywheel process or switched to a lighter model architecture if the current one is too heavy.
- Iterate and improve: Continuously measure changes in inference metrics and refine the model. Work in quick iterations to foster an inference-centric mindset and processes.
- Deploy and monitor: Once satisfied with the model’s performance, deploy it to production and continuously monitor its performance, making necessary updates and improvements.
This proposed process is highly customizable and flexible at each step, enabling teams to switch approaches quickly ensuring maximum efficiency and speed. Inference-centric AI development recognizes the ML lifecycle as an ongoing process, ensuring solutions remain robust and adaptive to data and concept shifts.

So, what wave of ML should you ride?
Hint: The inference-centric wave
The three waves of ML—model-centric, data-centric, and inference-centric—illustrate the field's evolution from algorithm innovation to data importance and, finally, to operational excellence. Each wave builds on the previous one, addressing emerging challenges and pushing the boundaries of what machine learning can achieve.
As we advance, the focus will likely shift towards integrating these waves into a cohesive approach that leverages each's strengths, driving further innovation and real-world impact. For now, catching the inference-centric wave will yield the most outstanding results.
At CloudFactory, we leverage an inference-centric approach to help our customers transition AI from the lab to real-world applications more swiftly and efficiently. We ensure that AI solutions are robust, scalable, and ready for production by prioritizing real-world performance metrics and focusing on seamless model deployment and operationalization. Our streamlined development processes and continuous performance monitoring enable quick iterations and improvements, allowing our clients to see tangible results and derive business value from their AI investments faster than ever before.