You can see natural language processing (NLP) at work everywhere. With voice-based assistants like Amazon’s Alexa or Google’s Assistant, many forms of NLP have already taken up residence in our homes. And with the popularity of AI-augmented design and content platforms, the potential of NLP is only growing.
While the future of NLP seems limitless, recent revolutionary tools like ChatGPT also illustrate the inherent challenges in NLP applications. It’s been widely reported that ChatGPT has issues when it comes to bias and accuracy. Even OpenAI’s CEO admits that its chatbot is “incredibly limited” and may reply with incorrect data.
The key to unlocking NLP’s potential lies in training models to understand the nuances of natural speech and language. That’s why many companies turn to a managed data labeling workforce to scale labeling operations. Whether you do this work internally or outsource, it's essential to find a workforce who can bring NLP expertise to the table and can deliver the high-quality outcomes you need.
Let’s dig deeper into the three essentials you need in an NLP workforce:
- Content and domain knowledge
- Smart tool choice
- Seamless blend of technology and humans in the loop
3 Data Annotation Workforce Essentials: Quality Data for High-Performing NLP
With more than 2M+ hours of NLP data annotation under our belts, we’ve uncovered three workforce requirements that are key to supporting quality data annotation for high-performing NLP.
1. Context and domain knowledge
Experienced NLP workforces understand how to accurately label NLP data and have experience working with the subjective nature of language. Understanding context and domain are two critical elements your NLP data workforce should be capable of providing.
-
Context relates to the setting or relevance of the content.
For greater accuracy, your data analysts should understand that words often have multiple meanings, depending on the text. For example, you would want them to tag the word “bass” accurately, knowing whether the text in a document relates to fish or music. They also must understand words are often synonymous, such as “Kleenex” for “tissue.” You might even want them to apply the knowledge that is not included in the text but is generally understood.
-
Domain expertise relates to the discourse model.
The vocabulary, format, and style of text related to healthcare can vary significantly from that of the legal industry, for example. This is especially challenging when you’re creating an NLP model for a domain that doesn’t already have a large, manually annotated collection of written text available for you to use. For accuracy, at least a subset of your data analysts should know key details about the industry your NLP application serves and how their work relates to the problem you are solving.
Domain and context capabilities are significantly limited with crowdsourced teams because they’re anonymous and don’t have access to peer learning or the benefit of aggregated lessons over time. You will get higher quality data with managed teams that become familiar with your data and increase their context and domain expertise with ongoing work on your project.
2. Smart tool choice
What comes first, the tool or the workforce? Some teams want to choose the tools first, while others prioritize the workforce. Or, if you’re lucky, you can find an all-in-one solution where the workforce is already paired with the best tool for your use case.
This illustrates the point of how important it is to consider how your tool and data team will work together. Using a tool your data analysts have experience with can provide valuable opportunities for built-in feedback loops that often improve model performance.
In general, you have three overarching options for NLP tools:
-
Build your own tool:
If you build your own tool, you have more control. You can make changes to the software quickly, using your own developers. But this also requires significant costly investments to build the tool. Then you must train and onboard your NLP workforce onto your tool, which can stall efforts to scale. -
Buy a tool:
There are different tools out there you can purchase, many of which offer auto-labeling and pre-labeling capabilities. While these features can increase speed, it’s important to keep humans in the loop (HITL) to handle edge cases and exceptions. Many data annotation workforces have deep expertise working with a particular partner or tool and can provide guidance on what tool to use for the highest quality results. -
Use an open-source tool:
There are open-source tools available for NLP. While free, NLP open-source tools can be difficult to use and come with the same commitment as building your own tool, which requires costly investments to maintain the platform over time. They also present barriers to scale as they lack robust dataset management.
Want to do a deep dive into labeling tools? You’re in luck! We’ve compiled all the information on the best tools out there in our guide on Data Annotation Tools for Machine Learning.
Before you build, buy, or vet an open-source tool, it’s a good idea to have discussions with your preferred workforce partner on what they recommend for your unique NLP use case. Be sure to ask questions to gain insight into their expertise working with particular tools, success using in-house tools, and ability to learn and implement licensed third-party tools. In some situations, like with CloudFactory’s Workforce Plus, you can bundle the tool and workforce together to simplify and accelerate your NLP data labeling for a single price on a single contract.
3. Seamless blend of tech and humans in the loop
For NLP projects, it’s important to create a seamless blend of tech and humans in the loop on your data production line. Think of it as your tech-and-human stack, combining people and machines in a workflow that directs tasks where they are best suited for high performance. That means assigning people the tasks that require domain expertise, context, and adaptability—and assigning machines the tasks that require repetition, measurement, and consistency.
As you can see in this task-progression graphic, as you move toward more difficult tasks, you’ll need more humans in the loop.
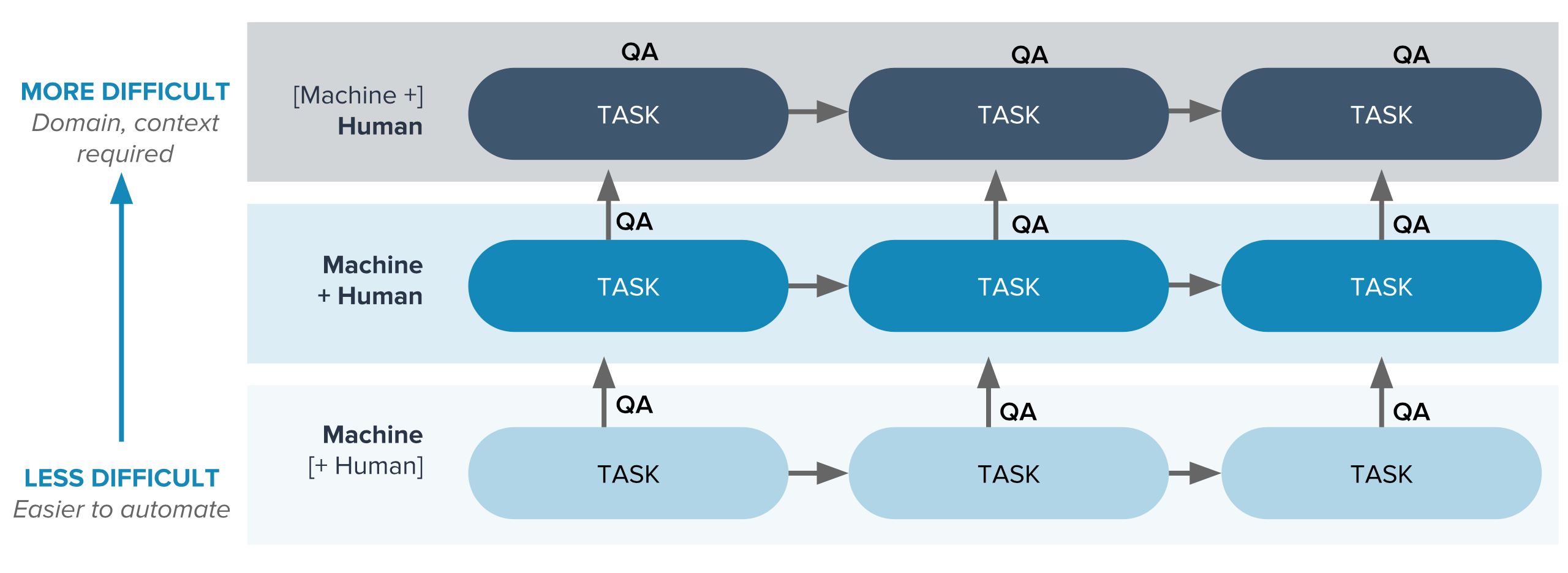 And when it comes to QA, consider the benefits of engaging managed teams in the process:
And when it comes to QA, consider the benefits of engaging managed teams in the process:
- They can make the blend between annotator and tool faster and easier by managing the repetitive QA process for you as part of the task progression.
- They can incorporate improvements prompted by QA learnings into your workflow. Anonymous teams don’t bring the progressive benefits of a managed team, which acts as an extension of your own.
Annotation for NLP is not a fixed process; it will change over time, and you’ll want the agility to incorporate improvements as you go. Reliability and trust are key factors to identify in your workforce solution. Look for a team that provides a closed feedback loop, where you have a single point of communication with your annotation team. Strong communication between your development team and the data analysts who are establishing ground truth for your models is critical here; it will ensure better model performance, accelerate deployments, and allow you to bring solutions to market faster.
Your Data Annotation Workforce Makes All the Difference
With any AI project, but with NLP especially, your workforce choice can mean the difference between winning the race to market or running out of steam before you ever finish. If you want to develop a high-performing NLP model, you need a strategic approach to your data production that includes processes, tools, and reliable people who are accountable for delivering high-quality datasets and who function as an extension of your development team.
If you want more ideas to bring your NLP solutions to market faster, check out our Ultimate Guide to NLP. To get more information on how CloudFactory can help you with text and audio annotation, labeling, tagging, classification, and sentiment analysis contact us!

Outsourcing NLP Workforce Strategy AI & Machine Learning Data Annotation
