

In last week’s post, we looked at how much data is necessary to train an autonomous vehicle. And that’s only the beginning. Not only do autonomous vehicles need to draw upon the entire human experience of driving – they need to be ready for real-world environments, which constantly evolve. For a self-driving vehicle to master the road, it needs vast amounts of information coming from a diverse range of sources.
The key to success lies not only in training the model in the first place, but keeping it refreshed to avoid repeating mistakes or failing to identify unusual conditions. Active learning provides a way to optimize the use of humans in the loop by identifying edge cases for human inspection.
What is active learning?
In machine learning, active learning is iterative supervised learning that allows an algorithm to query an information source to label new data points with the desired outputs. It can be used to overcome the data labeling bottleneck by dramatically reducing the number of manually labeled samples required.
Machine learning models require huge amounts of training data to perform well. But while the data is readily available, the sheer size of the data sets makes manual labeling impractical. At the same time, a supervised learning model cannot work without humans in the loop. And choosing a random subset of data for manual labeling doesn’t provide enough data diversity.
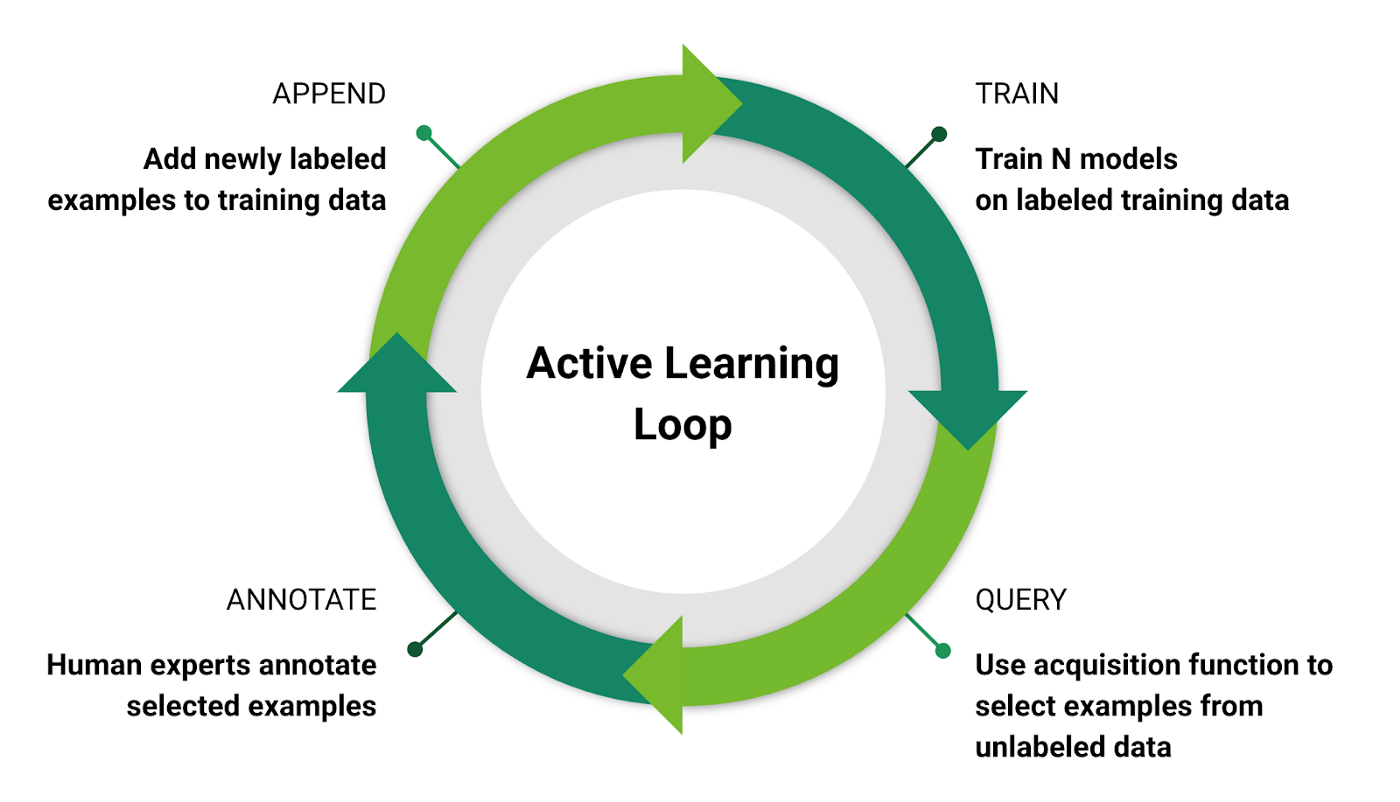
Active learning prioritizes data for manual labeling, thus greatly reducing the burden on people. It’s a process of continuous improvement that incrementally increases the accuracy of the model while keeping it refreshed with up-to-date training information. It creates a repeatable training loop:
- Training – The model is trained using available labeled data sets. At first, the model won’t be very accurate, due to the limitations of manual labeling of generic data sets.
- Query – The model selects unlabeled data, either using the least confidence strategy, margin sampling, or entropy, and then refers it for manual labeling.
- Labeling – Human experts label the selected data and append it to the training model. In each case, the model’s accuracy incrementally improves.
Source: Scalable Active Learning for Autonomous Driving: A Practical Implementation and A/B Test, NVIDIA AI
The key goal of active learning is to determine which data needs to be manually labeled. This is typically achieved using uncertainty sampling, where a threshold is set for the machine to decide whether or not to query the data. With autonomous vehicles, this threshold must be set extremely low, given that even the slightest error could mean the difference between life and death in a real-world scenario.
Here are the three main approaches to uncertainty sampling:
- Least confidence – Using this approach, the active learning model chooses data that doesn’t meet the confidence threshold. For example, if the model isn’t 99.9% certain what a particular object is, it will initiate a query for further analysis.
- Margin sampling – This approach helps correct shortcomings in the least-confidence strategy by incorporating the second-most likely label for the data. This gives the model the chance to differentiate between the two most-likely labels.
- Entropy – This approach measures the uncertainty of a random variable. This allows the system to use all possible label probabilities. The instance with the highest entropy value is queried.
What does this mean for autonomous vehicles?
One of the biggest training hurdles for autonomous vehicles is identifying edge cases. While training a self-driving AI system to recognize common objects and scenarios is relatively straightforward, teaching it to recognize unusual conditions and objects on the road is quite another matter.
Obtaining enough labeled data to account for these edge cases is another challenge. People can effortlessly and reliably perceive road conditions in almost any locale or environment. An autonomous vehicle must be able to perceive the same conditions as well as or, preferably, even better than a person.
Unexpected roadblocks, exotic animals, and unusual road signs are just a few more common examples. Then there are less common situations, such as a truck towing a trailer towing a quad bike, which a self-driving system could distinguish as two or even three separate vehicles.
Active learning works by detecting things the machine doesn’t recognize with adequate confidence and then referring them to people for labeling. For example, NVIDIA AI’s research found a three-fold precision increase when using active learning to train models to detect pedestrians at night.
Will active learning help innovators reach level 5 autonomy?
Given the enormous diversity of road conditions around the world, active learning offers a practical way to optimize the data labeling effort needed to achieve level-four and level-five autonomy. It’s a scalable solution combining the power of human expertise with machine learning, something that is critical for ensuring there are no blind spots when fully autonomous vehicles finally hit the global market.
One thing is clear, human-powered annotation will always be an important part of autonomous vehicle development and model maintenance. CloudFactory’s managed teams of data analysts provide scalable data labeling services for autonomous vehicle innovators. Do you need annotation help? Let’s talk.

Computer Vision Image Annotation AI & Machine Learning Automotive
