

The amount of data needed to maintain an autonomous vehicle (AV) is staggering. Current estimates suggest a level-five autonomous automobile in production generates between one and 20 terabytes per hour.
“Those are estimates of course, because no one has developed a Level-5 vehicle,” said Keith Rieken, AI solutions manager at Pure Storage, in an Automotive World webinar. “But this is a challenge because in order to train these neural networks, the amount of data required is even larger.”
Last week, we discussed training data hurdles and why it’s difficult to reach level-five autonomy for automobiles. Now, we’ll explore why collecting data is the biggest innovation speed bump of all.
Data as the new fuel for autonomous vehicles
AV systems are more data-hungry than almost any other AI application. After all, they need to be trained to recognize every object and environmental variable they have any chance of encountering in real-world scenarios. This includes a practically unlimited range of possible edge cases.
Obtaining enough structured data to make autonomous vehicles a reality remains an extraordinary challenge. Autonomous vehicles must process data from onboard sensors in real time, which is no small feat. For example, NVIDIA’s DRIVE AGX solution delivers 320 trillion operations per second (TOPS) of performance. That’s almost six times higher than Apple’s new Macbook Pro.
Where does all this data come from?
Autonomous vehicles use a combination of devices to recognize and interpret the world around them, including:
- Cameras, which can record 2-D and 3-D images and video
- Radar, which makes use of long-wavelength radio waves
- LiDAR (Light Detection and Ranging)
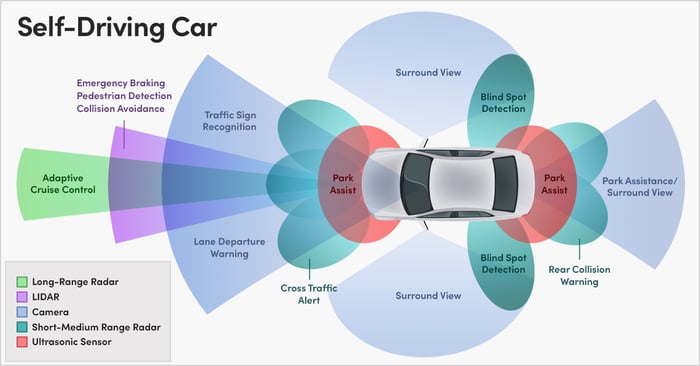
This diagram illustrates some of the features of a self-driving vehicle and the various types of data it collects and uses, including long-range radar, cameras, short and medium range radar, and ultrasonic sensor data.
Collecting this data requires using data other innovators make available or doing it yourself and scaling the process. Larger autonomous car developers deploy fleets of test vehicles to capture data. Recently, Tesla patented a method for sourcing training data from across its fleet of 500,000 customer vehicles and feeding it into its self-driving neural network.
Unfortunately, collecting all this data in-house using a limited fleet of test vehicles isn’t sufficient. Test vehicles typically operate in limited geographies, such as a small group of cities, to start. In the United States, on-road testing of automated vehicles is currently occurring in 17 cities. The U.S. government just launched the Automated Vehicle Transparency and Engagement for Safe Testing Initiative tracking tool to provide transparency about AV testing and performance across the country.
For self-driving cars to become more widely available, their AI systems must be trained using globalized data sets. This includes paying attention to factors like differences in rules, road signs, area wildlife, unusual obstacles, and weather conditions.
This global roadway data is available from global startup, Driver Technologies. Their free Driver Dash Cam app is for iOS and Android users worldwide. By collecting a wealth of anonymized data from users in 170+ countries, they’re contributing to the development of safer self-driving cars.
Continuous supply of data = continuous improvement
Training a self-driving vehicle is a process of continuous improvement. Autonomous vehicles can potentially be far safer than human drivers due to their abilities to make near-instantaneous decisions without being influenced by factors like emotion or fatigue. But to do this, they require a continuous supply of data which has been enriched by human-powered labeling.
Again, given the enormous diversity of driving conditions around the world, the only way to train a vehicle to drive better than people requires massive data and human expertise, leveraging the collective insights from billions of miles of individual drivers and fleets of test vehicles. Accurate image annotation will fuel the continued improvement of safe, self-driving cars.
To keep up with labeling big data pipelines, many autonomous vehicle development teams turn to outsourced workforces. CloudFactory helps automotive innovators including Luminar, Embark, and Driver prepare quality data to train and refresh their models. Do you need annotation help? Let’s talk.
Stay tuned for next week’s post about using active learning to train and refresh self-driving car algorithms.

Computer Vision Image Annotation AI & Machine Learning Automotive
