Artificial intelligence is revolutionizing businesses of all sizes, but it's only as good as its training data. If your data is low-quality, inaccurate, or incomplete, so is your AI model.
It’s like trying to drive to a new destination without a map. You may eventually get there, but it will take you longer, and you'll likely get lost.
There are many ways you can draw that map, but one of the more simple yet effective ways is to define what you want from your data accurately.
Quality AI training data begins with providing effective data annotation guidelines to your labelers.
The goal of creating annotation guidelines is twofold:
- To act as reference documentation to learn the specific use case. Data labelers will use them to seek out answers to specific questions. The guidelines should be logically structured and easy to scan.
- To enable knowledge transfer and standardization. The last you want is project disruption. If a team lead were to leave suddenly, the guidelines would provide the remaining team members with a clear understanding of how to annotate the data correctly.
This blog post features our top tips and tricks for creating effective data annotation guidelines. We want to help you deliver the best possible product to your customers, so if you follow these guidelines, you'll be well on your way.
Include the why, what, and how in your data annotation guidelines
Great annotation guidelines answer the three following questions:
- Why are you labeling?
- What should be labeled?
- How should it be labeled?
1. Why are we annotating?
Data labelers, like all people, find it easier to motivate themselves and make good, subjective decisions if the purpose of their work is clear.
Explaining the why gives your data labeling workforce context.
Here’s how you can share the why in your data annotation guidelines:
- Define challenges that your product or service aims to address for your customers.
- Explain any adverse effects of that challenge not being addressed.
- Outline how your product or service addresses your customers’ pain points.
- Spell out the role that high-quality data annotation plays in helping you achieve your business goals.
You don’t need to go in-depth during the introductory phase of your project. The goal here is to set expectations early on and give them a high-level scope of your project.
2. What should be labeled?
Next, you need to give clear guidelines on what should be annotated. Here, it's important to keep a few points in mind. Suitable data labelers:
- Know annotation. They can differentiate a polygon and a pixel-wise mask or object detection and instance segmentation.
- Don't know your unique use case yet. Every project is unique and comes with its own set of challenges and solutions. It’s always best to assume data labelers haven’t worked on a project exactly like yours before to allow room for critical thinking and problem-solving.
- Are tech-savvy but not machine learning engineers. Some data labelers are familiar with concepts like Intersection over Union, but the vast majority of labelers will best understand requirements written in plain language.
3. How should it be labeled?
General guidelines. Start with guidelines that apply to all classes and labels to be created. Good practice here is to outline:
- What annotation types are relevant (e.g., instance segmentation with masks).
- What objects to label and not label in an image.
- What to do in cases of ambiguous scenarios or uncertainty independent of object class.
Class-specific guidelines. Then, go into detail, giving instructions for each class used when annotation. Good practice here is to outline:
- Explanation of each class at a summary level (1-2 sentences).
- Visual examples of the class. Examples can either be screenshots of labeled data (preferred) or screenshots of images without existing labels.
- Edge cases that data analysts should look out for. For example, when they shouldn’t annotate this particular class, what other classes might be similar, and how to differentiate, etc. Visual examples can be helpful here.
Additional best practices to improve your data annotation guidelines
Next, let's quickly go through some additional best practices for writing annotation guidelines.
- Create a table of contents at the start of the document. This allows data analysts to quickly scan the document's content and understand how the information is organized.
- Write descriptive headings so that data analysts can easily find what they are looking for.
- Use the inverted pyramid. Put the most crucial information at the top of any section. Then, add important details. Add anything else of lesser importance at the bottom.
- Make use of bold text and bulleted lists. The human eye is drawn towards what visually stands out. Bulleted lists have the additional advantage of having a more precise structure than your ordinary paragraph.
- Beware of internal jargon and acronyms. Use plain language.
- Use short sentences with an active voice. This writing style helps with clarity and reduces cognitive load.
- Incorporate versioning. Include a revision history table with version number, date of update, primary author name, and a description of changes at the bottom of the document.
Below is an example of a sample guideline for one of our recent projects, ‘Waste in the Wild,’ that you can use as a template:
EXAMPLE: Waste in the Wild Data Annotation Guidelines

Clear data annotation guidelines with a table of contents help data labelers perform tasks efficiently, delivering the best possible product to your customers.
About the Project
The Problem
According to the World Bank, we’ll produce 70% more waste in 2050 than we are doing today if nothing changes. Our trash is becoming a global problem.
Out of that waste, at least 33 percent—extremely conservatively— is not managed environmentally safely. In many cases, it’s not managed at all!
Humans, nature, and animals suffer if we don’t handle trash correctly. Some of the effects of poor waste management are:
- Making humans and animals sick
- Polluting our water
- Increasing financial strain
The Solution
Many of you might have seen the movie WALL-E. For those that haven't, the main character is a waste collection robot tasked with cleaning up Earth. This data we are creating enables the creation of actual WALL-E robots that can collect and sort garbage automatically. This technology could drastically reduce the amount of waste that’s not processed at all today or miscategorized.
Task Guidelines
General Guidelines
Here, you can find a set of instructions for how to handle edge case labeling for all classes. For this project, we are performing instance segmentation on waste of all types (more details in class-specific guidelines).
Objects with Holes
Obfuscation
Please note that for us to be able to create a non-uniform object as we do above, we need to make use of the Mask tool or label the two separate parts using another tool, select both, and then merge them into one object.
We only want to label an object if ~50% percent of it is visible (more in the “Partials” section).
Partials
Partials are what we call potential labels that are not 100% visible because of a couple of reasons:
- They are located at the edge of an image, and part of the object is cropped out.
- They are hidden behind another object.
- They are damaged or broken somehow, meaning that a part of the object is missing.
For all these cases, we only want to label the partial object if we can see 50% of the object. Please note that 50% is a rough estimate. If you label something where only 40% is visible, that is fine. For example:
We would actually encourage you to label something when in doubt. Don’t spend too much time estimating how many exact percentages of an object you can see.
Wrong Rotation
If you find an image with an improper rotation like below, set the image status to “skipped.” Please inform your team lead if you encounter many photos with the wrong rotation.
Low-Quality Image
In cases where the quality of the image is not good enough to label, set the status to “skipped.”
Low-quality images include:
- Too dark/light
- Blurry
- Out-of-focus
- Too zoomed in/out
- No relevant objects to label
Background Objects
We only want to label foreground objects. We define background objects as being:
- Not in focus
- Too far away from the camera to be distinguishable
- Blurry
As a guiding rule, we are mainly interested in objects up to 10 meters away from the camera. Everything else we see as background.
Examples (the marked red area is foreground):
Class-Specific Guidelines
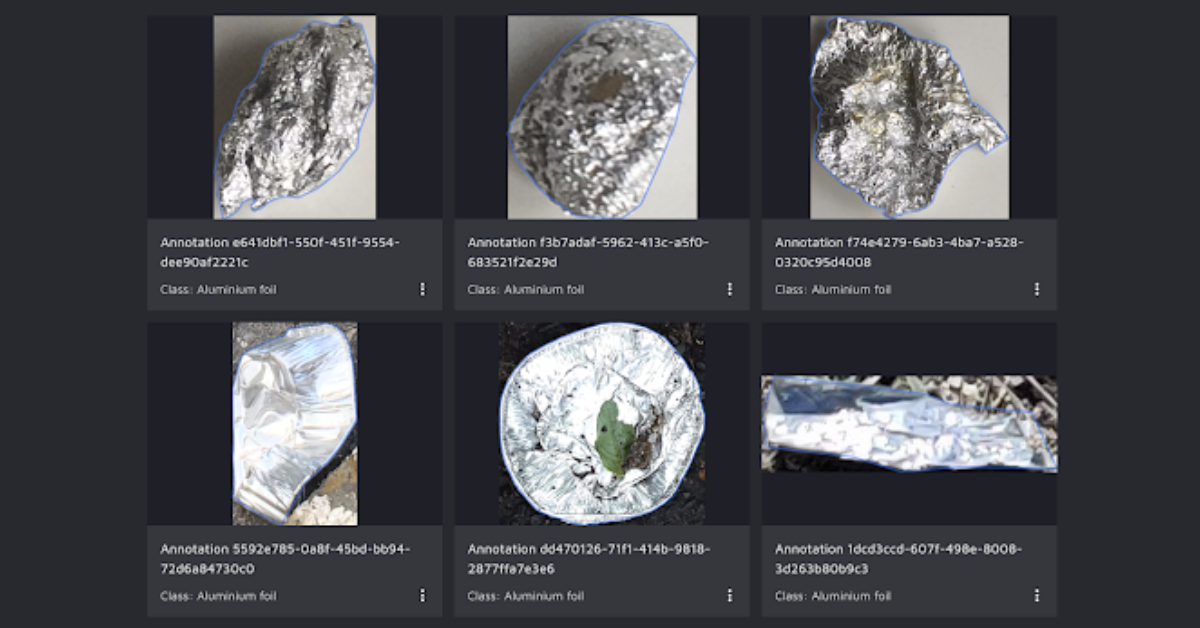
Aluminum Foil
With aluminum foil, we mean all that silvery foil you might have in a kitchen drawer at home.
Visual examples:
Characteristics:
- Usually silver-colored, but can come in other colors as well
- Highly reflective
- Mainly seen in two different versions
- Foil sheets used as a paper replacement
- Foil containers mainly used for food
Look out for:
- Sometimes, you might have candy wrappers or crisp packets made of aluminum foil. However, we use the plastic bag wrapper super category and the “other plastic wrapper” category for those.
- There are also aluminum blister packs made with aluminum foil. However, we classify with the class “blister pack.”
- Finally, there are aluminum cans. Those we classify with the class “can.”
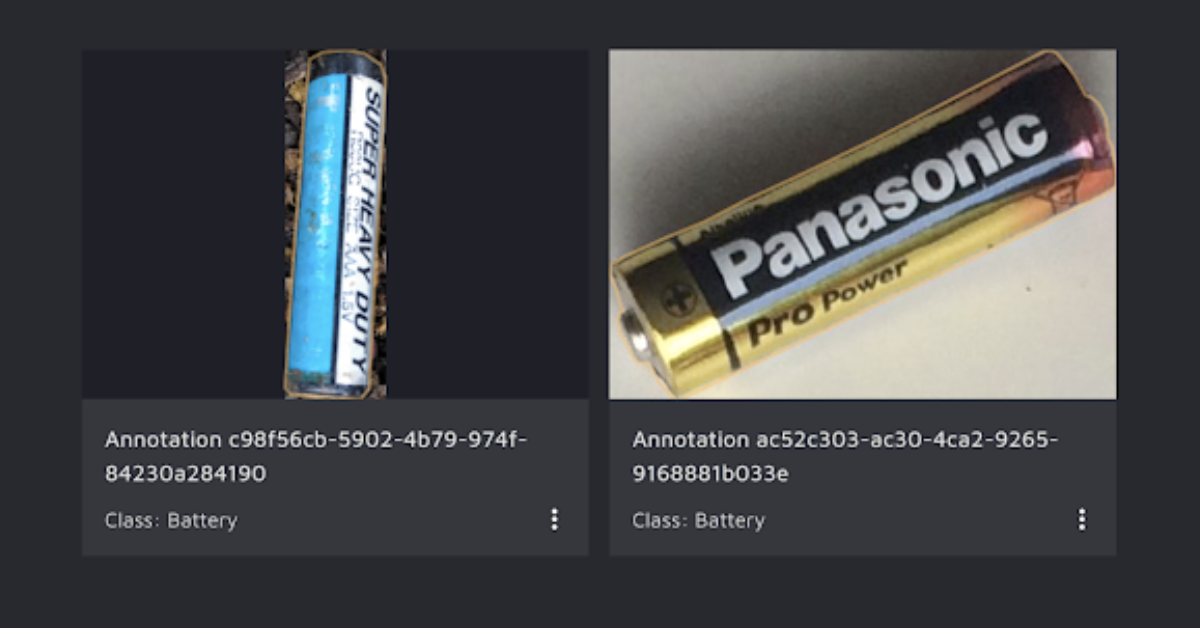
Battery
This class covers all types of batteries, from large car batteries to small AAA ones.
Visual examples:
Characteristics:
- Can come in many shapes, colors, and forms, but the most common types are:
- Cylinder-shaped batteries (see above)
- Coin-like batteries
- Industrial box batteries with visible plus and minus pools
- Usually have marked plus and minus pools
Look out for:
- What if there are visible batteries inside a larger piece of waste – for example, a remote control? If so, label the remote control first and then the batteries “on top” of the original annotation.
Revision History
Version Date By Description 1.1 16 March, 2023 John Added visual examples for label classes, attributes, and image tags 1 12 March, 2023 Sarah Wrote the initial draft





Your partner for high-quality data annotation
If you found this blog post insightful, you'll enjoy our on-demand webinar, How to Avoid the Most Common Mistakes in Data Labeling, which goes even more in-depth into data annotation guidelines. It also gives you insider knowledge on how to incorporate humans in the loop throughout development, deploy an adaptive AI-assistance approach, and get to the root cause of quality issues.
The webinar is a must-see, but if you don't have the time, this blog post provides a nice recap and outlines 5 of the most common pitfalls in data labeling.
CloudFactory has helped its clients train, sustain, and augment AI models for over a decade with a powerful mix of human experts and leading workforce management technology. We provide high-quality support for even your most time-sensitive, vital tasks.

