How you acquire data is vital to the ethical credibility of your AI system. In CloudFactory’s recent Ethics and AI survey1, 35% of IT decision makers deemed the ethics of data acquisition as extremely important. I see that focus only growing over the coming years as AI systems come under greater scrutiny.
In the first blog post in this series—The Need for Ethically Designed AI Systems—I considered why we might need to weave ethics into the AI systems we design. In this post, I’ll take you on a deeper dive into one of the most important areas of ethics in AI system design: The acquisition of training data.
Getting rights to use data for model training

The law is full of grey areas, and that of copyright and fair use is no exception. The bulk of legislation that governs copyright and fair use was written around the turn of the millennium, a period when deep learning and neural networks were theoretical and confined to academic papers. Because it’s impossible to write legislation for something that exists only in theory, the law does not cover using data for training a commercial model.
This lack leads to disagreements between rights holders and some data scientists. The rights holders believe that copyright covers training data under the Digital Millennium Copyright Act because the end product is a commercial asset. But some data scientists disagree with this view, saying that publicly available internet data, which isn’t directly being used commercially, is not covered by copyright protection and instead falls under “fair use.” In its review of hiQ Labs v. LinkedIn 2022, the 9th U.S. Circuit of Appeals ruled that data scraping from the internet is legal, adding another twist to the story.
Even when data comes from an internal source and copyright isn’t at stake, you still have to consider what rights you have to use—and sometimes even retain—that data. For instance, will using data put you in breach of contract? Many companies maintain massive legacy databases or data lakes filled with usable information, much of which may be off-limits because of data protection and deletion clauses in client contracts.
Making individuals unidentifiable
.png?width=960&name=General%20Data%20Protection%20Regulation%20(GDPR).png)
What’s next after sourcing your training data and clearing copyright hurdles? Unfortunately, even more legislation! The General Data Protection Regulation (GDPR) says that, in any dataset, individuals should not be individually identifiable without their explicit permission. IT professionals largely agree: 87% of those responding to our survey said ethical data cleansing is important when designing an AI system2. Even so, legal precedent does not yet exist around whether multiple data points acting as proxies for personally identifiable data fall under GDPR or not.
But, wait. You might think that you’d need a vast amount of data points to identify one individual. Surely you could get around the issue by using fewer data points? Unfortunately, no.
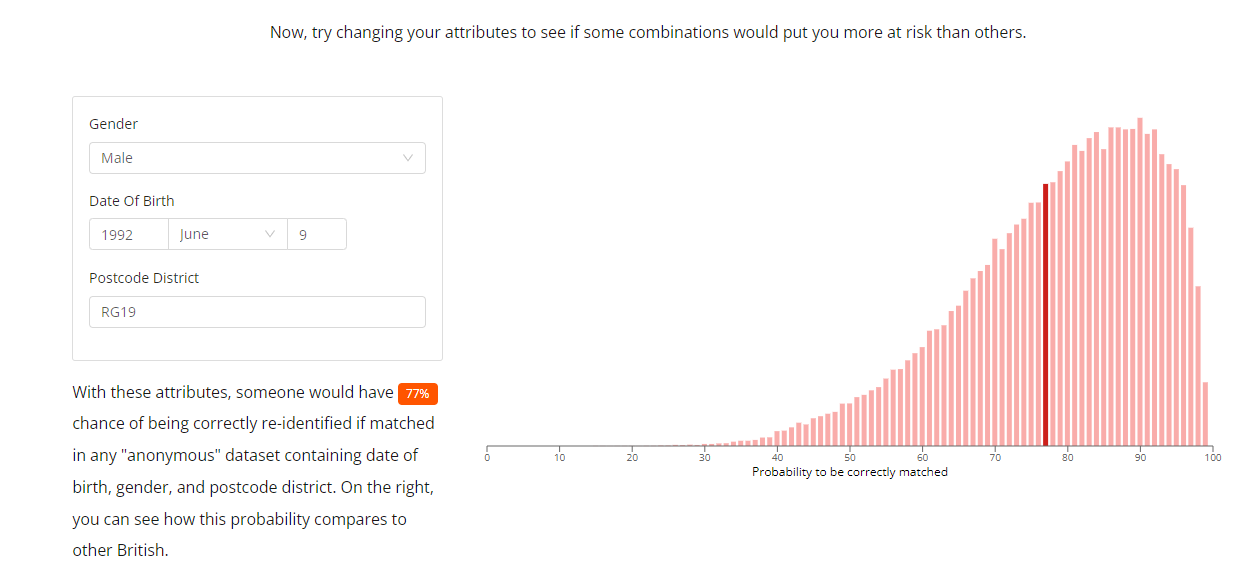
Imperial College London’s tool, Too Unique to Hide, illustrates that you need just a few variables to identify a unique person. For instance, by knowing just three attributes—my date of birth, postcode (ZIP code in the U.S.), and gender—you have a 77% chance of identifying me as a unique individual.
Here is a screenshot from the tool based on my inputs:
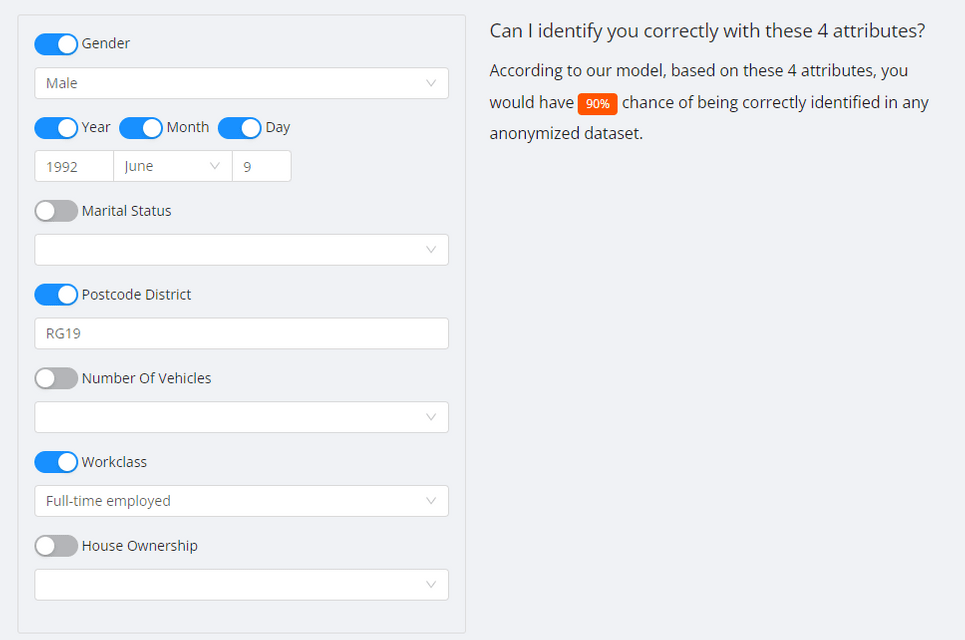
If you add another attribute—that I’m employed full-time—the chance that someone will identify me as a unique individual jumps to 90%!
Obfuscating data
If you believe data may make individuals identifiable, even by proxy, the next step is to remove that data. The downside to removing information is that you end up with a sparse, unusable dataset.
For instance, if your business is to provide mortgages and you want to know whether a person will repay before retirement age, you need their date of birth. But as demonstrated by Too Unique to Hide, date of birth is one of the most revealing proxy data points. By adding two other seemingly harmless pieces of data likely to be included in a mortgage application—gender and location—your applicant becomes easily identifiable.
This “identify me, don’t identify me” quandary leaves companies and lawmakers in an awkward position. Everyone wants to uphold the consumer’s right to privacy, but companies need consumers’ personal data to provide products and services. There are possible solutions to these data privacy issues, but most require some kind of compromise.
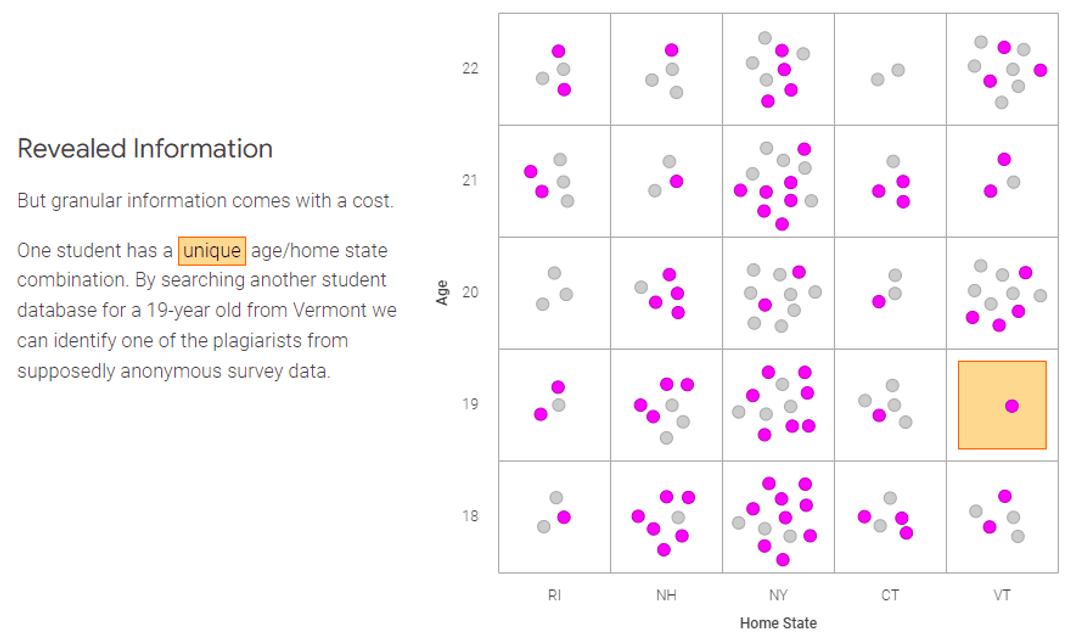
Consider randomized response, which gives privacy to each individual in exchange for a degree of accuracy. Google’s People + AI Research team created a practical, interactive example of how you can use randomized responses to mask personal data in your datasets.
But randomized response is not a cure-all. This screenshot from the interactive model shows that a student—age 19, from Vermont—has been identified as a plagiarist after completing a supposedly anonymous survey.
Covering edge cases
Suppose you’re free and clear where rights are concerned, and people are not personally identifiable in your datasets. Your goal is to ensure that your machine learning model applies to all use cases, including those on the edges. There is little value in producing a machine learning model that covers only typical use cases. The real value comes when you can cover unusual scenarios and edge use cases—a challenge because these cases are uncommon and hard to find.
To make the challenge even steeper, most models need a minimum of 100 examples to start training and 1,000 examples to get to a reasonable degree of accuracy. Tools within the computer vision field can help you visualize your dataset and cluster similar types of objects so you can focus on labeling that data or sourcing more data if you don’t have a large enough pool to pull from.
Avoiding over-representation
This clustering, however, gives rise to another danger: The danger of over-representing populations in your dataset, leading your model to be innately biased. Over-representation rarely happens intentionally; in most cases, the first time model developers learn that they’ve over-represented a population is when the story comes out in the media.
In over-representation, the proportion of the majority or the minority population is too large. You don’t need the exact proportions as seen in the world of your data, but the distribution does need to be representative of the population your model addresses.

For instance, consider Labeled Faces in the Wild, an extensive dataset of more than 13,000 faces. In the early days of machine learning, data scientists frequently used this data to train facial recognition models—yet it contains 78% male and 83% white faces, a considerable over-representation of two demographics within the dataset. The problem is so significant that Labeled Faces in the Wild now comes with a warning:
“Many groups are not well represented in LFW. For example, there are very few children, no babies, very few people over the age of 80, and a relatively small proportion of women. In addition, many ethnicities have very minor representation or none at all.”
As another example, software frequently used in the U.S. to assess the risk of re-offending was highly biased against Black people. The U.S. has a well-documented, high incarceration rate, and Black people comprise a higher-than-average proportion of that population. The result? Training a model based on that data, even with race excluded, caused the model to use race as a defining variable for re-offending rates.
Awareness is the first step towards ethicality
There are no easy solutions to data ethics. You’ll always have to make trade-offs between accuracy and ethicality when dealing with data. The best way to ensure you’re as ethical as possible is to be mindful of the issues. Most data ethics issues stem from people acting unconsciously or ignorantly rather than maliciously.
Check out the Open Data Institute’s Data Ethics Canvas; you can use it to guide you through your decisions as you design and build your models.
Please get in touch if you’d like to learn more about how CloudFactory can help you feed accurate, high-quality data into your models.
–
1 CloudFactory’s Ethics in AI Survey, with 150 respondents, was conducted by Arlington Research in March 2022.
2 CloudFactory Ethics in AI Survey.