Segmentation labeling poses a significant hurdle even for seasoned data scientists and ML engineers.
While arguably not the absolute pinnacle of complexity, it often marks a critical point in a developer's journey—a moment of bewilderment leading to a deep dive into the intricacies of neural network architectures, evaluation metrics, and intricate code.
This blog post examines the five challenges in segmentation projects that developers commonly encounter that can disrupt workflow, challenge the team, and hinder the overall process.
These issues can lead to inefficient resource use and critical delays in meeting deadlines, sometimes resulting in project cancellation.
I'll discuss the following challenges:
- Lack of proper data, insufficient data quality, and noisy data
- Human-in-the-loop integration
- Machine learning model interpretability
- Incorporating contextual information
- Resistance to concept drift
But before discussing the five challenges, let's define segmentation labeling.
What is segmentation labeling?
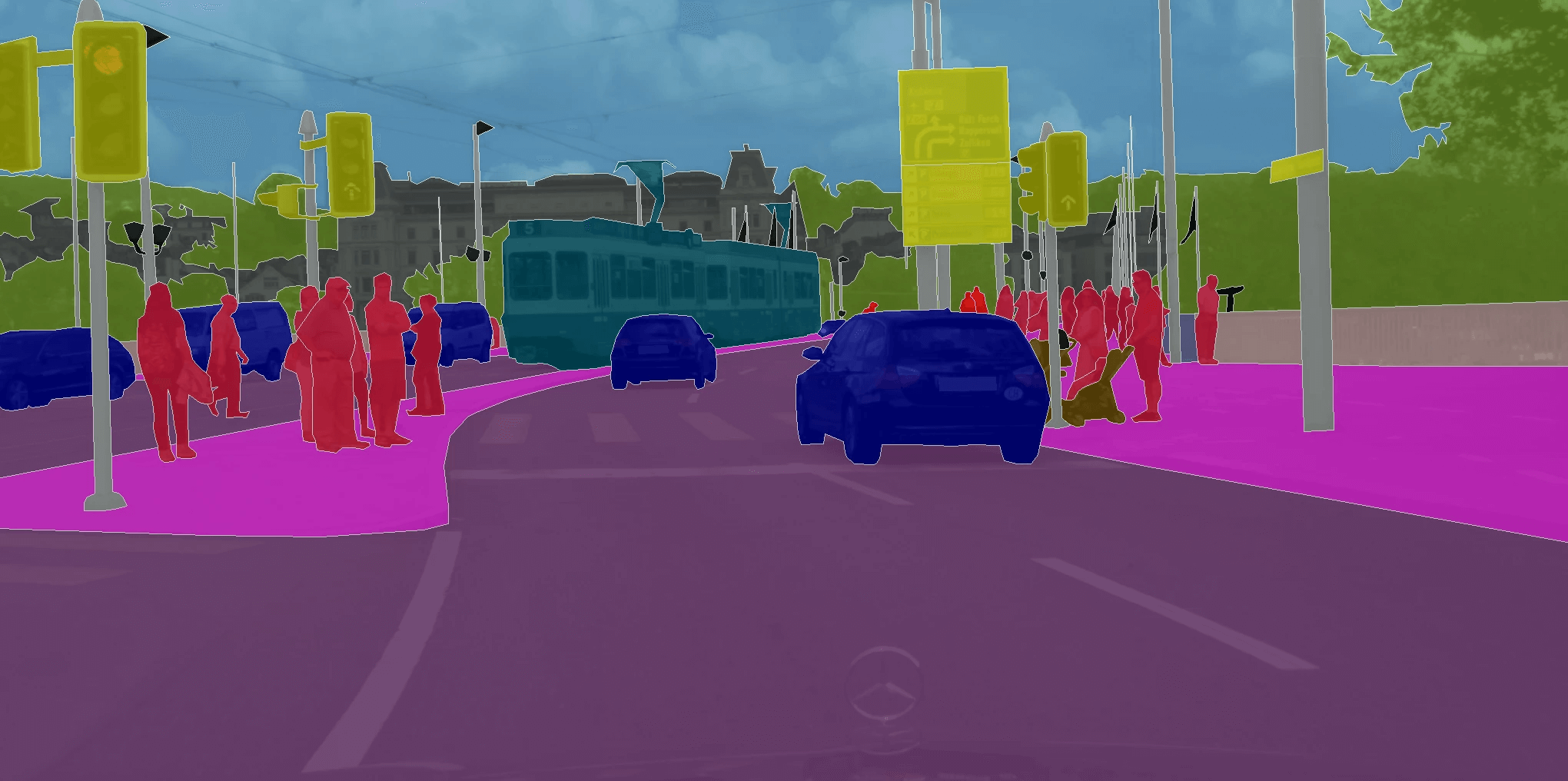
Segmentation labeling is the process of dividing an image or data point into segments or regions and assigning specific labels to those segments.
The process of gathering and annotating data for solving one of the segmentation tasks is called segmentation labeling. It incorporates approaches, tools, and techniques for dividing visual data into specific segments according to your project’s taxonomy.
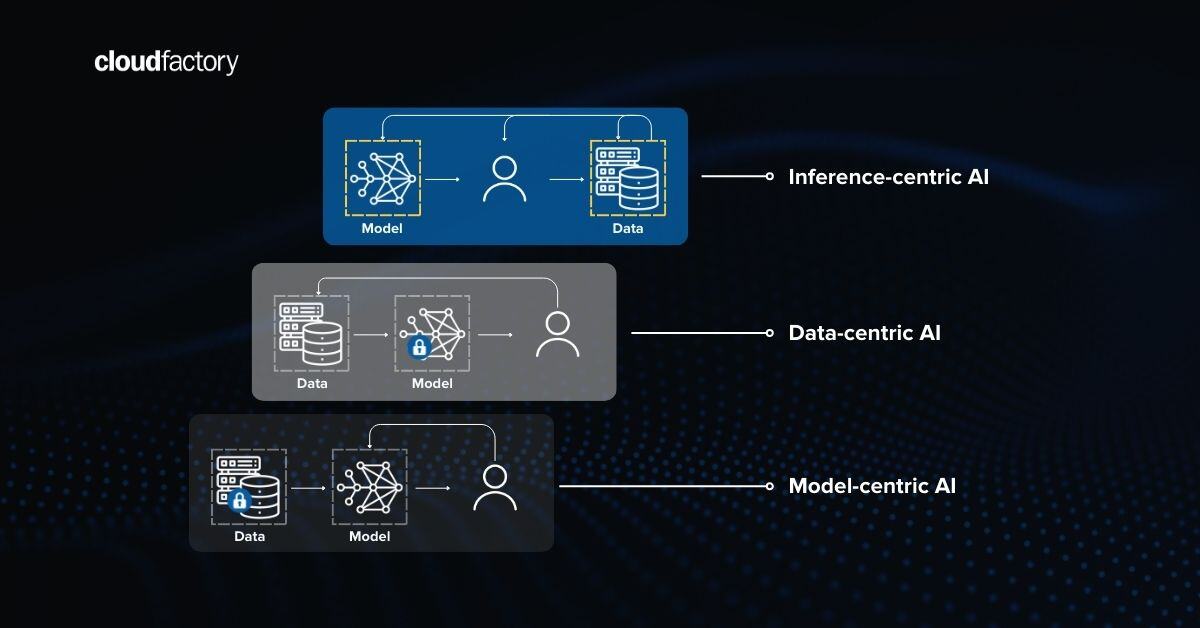
Developers prioritizing a data-centric approach in ML segmentation development view data, especially segmentation labeling, as a critical factor in a project's success.
What types of segmentation are used in labeling data for computer vision models?
Semantic segmentation, instance segmentation, and panoptic segmentation are three fundamental techniques in computer vision, each serving a distinct purpose in labeling and understanding visual data.
To gain more detail into these types of segmentation techniques, visit our blog post, Achieving business goals: The role of segmentation labeling in computer vision.
Five image segmentation challenges in machine learning
-
Lack of proper data, insufficient data quality, and noisy data
I'll be blunt: no matter how sophisticated your model design is, poor data can spell disaster. In the world of ML, the saying “the quality of your AI solution is only as good as the quality of the data it was trained on” holds true.
Therefore, investing time and resources in the initial stages of the ML lifecycle is crucial—data gathering, cleansing, annotation, and validation. By ensuring your data is clean, complete, and relevant, you lay the foundation for a model that delivers exceptional results.
Here are some examples of the issues that can arise without quality segmentation data:
- You're trying to segment geospatial images of flooded areas in neighborhoods where the houses sit close to the shoreline but also have backyard swimming pools. If labeled incorrectly, your model will pick up the concept of "water" but will be inaccurate if it includes the water from the pools.
- You might come from a retail domain and be tasked with detecting products on the shelves to identify whether they need replenishment. You find a suitable dataset with only the first item labeled on each product line. Is the data okay? Probably yes. Are the labels okay? You may want a comprehensive approach to the task.
- Now, what if you're segmenting small objects on massive 5000x5000 images captured through UAVs? One approach might be subdividing the images into smaller, more manageable segments for more precise and efficient object segmentation. But what other approaches are also available?
My takeaway: High-quality data is the lifeblood of successful ML solutions. While expensive to acquire or get in-house, neglecting it guarantees failure. Don't fall into this trap. Even if you do not believe in data-centric machine learning, you cannot ignore that you need it in place for the success of your solution.
-
Human-in-the-loop integration
The concept of humans in the loop for segmentation labeling is appealing as it promises to minimize manual work while maintaining human oversight for high-quality output. But it presents challenges.
It requires a delicate dance between human annotators, AI-powered assistants, and robust management and technology that requires you to:
- Orchestrate collaboration: Blend the strengths of human intuition and automation seamlessly.
- Manage effectively: Ensure efficient workflow and maintain high-quality standards
- Technologically empower: Integrate robust AI-powered assistants to support human annotators.
Building this infrastructure in-house can be daunting. This is where third-party annotation services can come in to manage the entire process effectively.
They can also provide cutting-edge AI tools to streamline the annotation process, improve accuracy, and deliver high-quality labeled data that meets your specific needs.
My takeaway: Claiming to have human-in-the-loop integration is not something all companies can defend. Be cautious and verify their true capabilities. Don't be fooled by mere claims; demand evidence of their expertise and commitment to delivering high-quality data.
-
Machine learning model interpretability
You've prepared your data, built your segmentation model, and trained it diligently. But, its performance falls short of expectations, leaving you baffled and a bit anxious.
The problem? Without interpretability, understanding the model's decision-making process and segmentation decisions under the surface is challenging.
Unfortunately, even today, providing meaningful explanations for the models’ decisions can be a sworn challenge for the developers. This is especially true for complex, multi-layer, and often even multi-model segmentation algorithms.
Still, it should not knock you down and make segmentation a non-viable option that deters you from exploring segmentation. Especially since there is some advanced research offering some interpretation algorithms.
My Takeaway: By working in small iterations and breaking down your segmentation project into manageable chunks, you can continuously assess interpretability needs throughout the process.
-
Incorporating contextual information
Unsurprisingly, your segmentation solution’s results can often benefit from contextual information, but providing such input is a struggle on all levels.
Adding contextual information often entails intensifying segmentation labeling efforts, increasing model complexity to accommodate additional inputs, and delving into the intricacies of model decision-making.
Each of these steps harbors a multitude of hidden sub-questions and associated costs. Given these challenges, the question arises: is pursuing contextual information worth the effort?
Realistically, if analysts promise a potential 10% or more improvement in model metrics, for example, mean Average Precision, many teams and researchers might be willing to navigate these challenges, costs, and potential drawbacks, opting for a high-risk, high-reward approach.
My takeaway: By understanding the pros and cons of incorporating contextual information into segmentation efforts, you can ensure your decision will yield the best result for your specific project.
-
Resistance to concept drift
Concept drift is a well-known challenge among developers that is not always obvious and predictable but leaves you with a massive hole in your solution.
From the technical point of view, concept drift occurs when the statistical properties of the context of the target variable change over time and start negatively impacting the performance of your segmentation models.
If we go deeper, this means that the target your model was trained on is no longer 100% relevant due to some changes.
A great example of concept drift is when your target suddenly changes. For example, you were tracking Arctic foxes' migration in the tundra through geospatial images, but when winter came, animals changed the color of their fur, and your model lost them because of their natural camouflage.
And that is it - you have a model that cannot help you in new circumstances.
My takeaway: Developing models or concepts (such as data flywheel – an approach to get the most value out of data) that can help models last longer and be less vulnerable to concept (or data) drift is essential to modern research in the segmentation field.
How CloudFactory addresses segmentation challenges
The challenges of segmentation tasks in computer vision are industry-wide. While addressing them is an individual team's decision, recognizing and discussing potential solutions is crucial for every Data Scientist and ML Engineer.
How does CloudFactory address a lack of proper data, insufficient data quality, and noisy data?
CloudFactory believes in a data-centric ML solution development approach and agrees with the statement that “data is the new oil.”
We offer a combination of manual, semi-automated, and fully automated tools to assist with annotation efforts.
We support the various segmentation annotation types in Accelerated Annotation, our best-in-class data labeling and workflow solution.
How does CloudFactory integrate humans in the loop?
Humans in the loop was CloudFactory’s initial focus. After many years in the field, we now provide an integrated human-in-the-loop team that is known in the market, well-trained, has real experience on various cases and in different domains, and professionally managed by industry experts.
CloudFactory also offers the Accelerated Annotation bundle that delivers superior-quality training data by integrating AI-powered automation and human expertise.
What is CloudFactory's approach to machine learning model interpretability?
CloudFactory's approach focuses on providing timely and valuable model insights through its Accelerated Annotation platform.
One of the key features of our tool is the ability to generate saliency maps using D-Rise and Grad-CAM algorithms for various models. This feature provides a visual representation of the model's attention on specific input features, allowing expert annotators and machine learning developers to better understand the model's decision-making process.
By understanding how the model is making its predictions, data annotators can refine the labeling process to improve the quality of the data and ultimately lead to more accurate and interpretable models.
How does CloudFactory incorporate contextual information into segmentation solutions?
CloudFactory leverages its expert workforce and annotation automation tools.
While CloudFactory doesn't directly develop multi-input neural networks, it excels in segmentation labeling, making it easy to incorporate contextual information.
Its expert annotators, aided by annotation automation features, can efficiently add tags, attributes, and other relevant contextual information.
Still, having a well-defined project taxonomy before the labeling process begins can significantly streamline the annotation process.
How does CloudFactory handle the resistance to concept drift?
You cannot do much with concept drift, as you are no prophet. The only thing that can save your nerves if the drift hits you is knowing how to address it.
While predicting concept drift is impossible, CloudFactory's data flywheel approach effectively mitigates its impact. Our products and systems are designed to facilitate the flywheel cycle, enabling prompt adaptation to changing data patterns.
By adhering to best practices, adopting suitable tools, and anticipating potential difficulties, you can streamline segmentation solution development and achieve accurate, reliable, and successful end models.
Need a hand with segmentation labeling or want to delve deeper into Vision AI decision points?
Download our insightful white paper, "Accelerating Data Labeling: A Comprehensive Review of Automated Techniques," and discover how to streamline your segmentation process and make informed Vision AI decisions.