A growing number of businesses are seeking to apply artificial intelligence (AI) to innovate customer experience and launch disruptive products. If your company is among them, you will need to label massive amounts of text, images, and/or videos to create production-grade training data for your machine learning (ML) models. That means you’ll need smart machines and skilled humans in the loop.
“Firms achieve the most significant performance improvements when humans and machines work together,” wrote Paul Daugherty and Jim Wilson in Harvard Business Review, about their research at Accenture involving 1,500 companies. “Through such collaborative intelligence, humans and AI actively enhance each other’s complementary strengths: the leadership, teamwork, creativity, and social skills of the former, and the speed, scalability, and quantitative capabilities of the latter.”
After a decade of providing managed, trained teams for data labeling, we know it’s a progressive process. You will constantly evolve and change it to meet your business and technical objectives. That is, the labeling tasks you start with today are likely to be different in three months. Along the way, you and your data labeling team will find better ways to label training data for improved quality and model performance.
On the tooling side, we’ve learned that the best data labeling, or data annotation tools, are user-friendly and break the work down into atomic, or smaller, tasks to maximize labeling quality. When you transform a complex task into a set of atomic components, it's easy to measure and quantify each of those tasks. After all, what you can measure, you can improve. It also allows you to identify which tasks are best suited to people and which ones can be automated.
So how do you choose the data labeling tool to meet your needs? In our work on more than 150 AI projects, we have found these steps to be critical in choosing your data labeling tool to optimize both your data quality and workforce investment.
1. Narrow your tooling choices based on your use case.
Of course, the kind of data you need to label will determine the tools available for you to use. There are tools for labeling data text, image, and video. Some image labeling tools also have video labeling capabilities. Tools vary in annotation features, quality assurance (QA) capabilities, supported file types, data security certifications, storage options, and much more. Labeling features can include bounding boxes, polygon, 2-D and 3-D point, semantic segmentation and others. You’ll want to assess exactly what features will provide you with the appropriate quality data, based on your use case and the domain where your ML model will be deployed.
Each data type brings workforce challenges. Text labeling often requires data workers to have context and the ability to make accurate, subjective decisions consistently across an entire dataset. Image labeling can require context but of the three data types, images are among the easiest to spin up teams to label. Scaling video labeling is significantly more challenging. Ten minutes of video contains between 18,000 and 36,000 frames, at a rate of 30-60 frames per second. Frame-by-frame video labeling is a time consuming and specialized skill that requires hands-on training and coaching to achieve maximum accuracy. A strategic combination of tool-based automation and people make this process easier and faster.
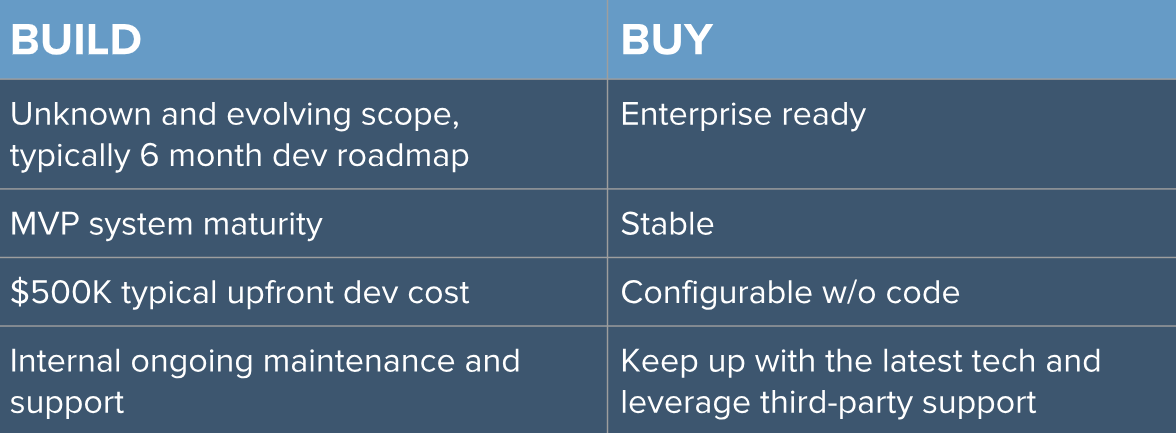
2. Compare “build vs. buy” benefits.
If you build your own tool, you will have more control to make changes quickly, using your own developers. You don’t have to worry about fees when the software scope changes. You also can apply technical controls to meet your company’s unique security requirements. Keep in mind, when you’re building a tool, you're up against unknown and evolving scope. You may not be sure of all the requirements at the outset.
It typically takes six months to develop software and infrastructure that can take an ML project from model validation to production. Any tool you develop will require maintenance. You can either maintain and support your own tool or you can keep up automatically with the latest tech for a commercial tool and leverage their third-party support.
There are commercial tools available to buy. You'll typically get an enterprise-ready solution that’s stable and you can configure with the features you need, usually without a lot of development time. Look for a tool that integrates well with the work of your data labeling teams and includes a data quality framework to ensure the integrity of your final datasets.
There is a third option. You can use an open source tool and support it yourself, or use it to jump-start your own build effort. There are many open source projects for tooling related to image, video, natural language processing, and transcription. Evaluating these tools can give you an idea of what you want to include in your own product and how you might do it, should you elect to go down the build path.
Despite the level of commitment involved with building your own tool, there are some solid benefits. Specifically, you can:
- Establish your own process within the tool of your choice. This is often where you can spot and leverage competitive differentiators.
- Mitigate unintended bias in ML models by configuring the tool according to your needs. Using any off-the-shelf tool could introduce their bias in data annotation tasks.
- Make changes to software quickly and with agility, using your own developers. You don’t have to worry about fees when the software scope changes.
- Exert greater control over security for your system. By having the tool in your stack, you can apply the exact technical controls that meet your company’s security requirements.
- Select the workforce of your choice to help achieve your objectives, instead of being locked in with one provider. When you own the tool, the workforce can plug into your task workflow more easily.
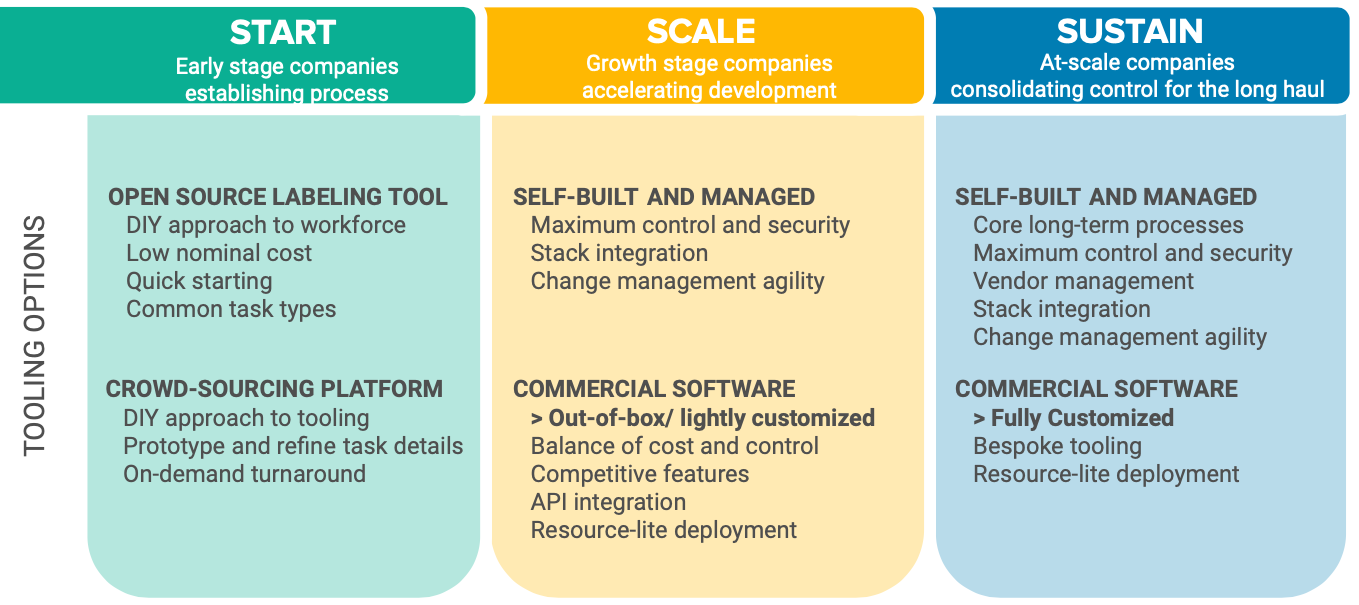
3. Consider your company size or stage.
Early-stage companies should prioritize different factors than companies that are scaling rapidly or already operating at scale.
If yours is an early-stage company that is establishing a process, and you use open source solutions to build your own tool, you’ll have to find your own workforce. You could choose crowdsourcing, and leverage that vendor’s tooling platform. Keep in mind, with crowdsourcing, your data workers will be anonymous and often unvetted, so you won’t get the benefits that come with working with the same team over time. That means context and quality of your data will suffer. Whether you plan to build or buy, be sure to ask workforce vendors about their experience with tools and whether they can provide recommendations.
If you are accelerating development as part of a growth-stage company, open source tools provide more control over security, integration, and agility to make changes. If you choose commercial tooling software, you typically can configure and deploy some competitive features.
If you are operating at scale and looking to sustain that process over time, open source tools are well planned and tested. You’ll likely have core long-term processes and stack integration that give you maximum control over security and the agility to make changes. At this level, if you’re using commercial software, you typically can get bespoke tooling that is fully customized for your needs and doesn’t require heavy development resources.
4. Don’t let your workforce choice lock you into a tool.
Tool and workforce can seem a bit like a chicken-or-egg choice. Some teams want to choose their tool first, others prioritize choice of workforce. We know that your workforce choice can make or break data quality, which is at the heart of your model’s performance. That’s why it’s important to keep your tooling options open.
Ideally, you want a workforce that can quickly adopt your tool, and help you adapt it to better meet your needs. It’s important to have a closed feedback loop with your data workers. As their familiarity and context with your data grows, they will bring valuable opportunities for you to streamline your process. They can suggest adjustments for your process and tool that can introduce competitive differentiators for the ML models you’re developing.
Managed teams deliver higher accuracy than crowdsourced teams, based on a study conducted by data science platform Hivemind, which provides a data labeling tool for natural language processing (NLP). Your labelers should be screened for proficiency with labeling tasks and receive ongoing training to improve their skills. You will achieve higher accuracy when the workforce operates like an extension of your team.
5. Factor in your data quality requirements.
Many tools include QA features, and you can even automate a portion of your QA. However, even when you are using time-tested automation for a portion of your data labeling process, you will need people to perform QA on that work. For example, optical character recognition (OCR) software has an error rate of 97% to 99% per character. On a page with 1,800 characters, that’s 18-54 errors. For a 300-page book, that’s 5,400-16,200 errors. You will want a process that includes a QA layer performed by skilled labelers with context and domain expertise.
There are a few managed workforce providers that can provide trained workers with extensive experience on labeling tasks, which produces higher quality training data. Be wary of locking into a multi-year contract with your workforce vendor. If your data team isn’t meeting your quality requirements, you will want the flexibility to test or choose another workforce provider without penalty.
Think Big, Start Small, and Scale Fast
Your choices about tooling and workforce will be important factors in your success as you design, test, validate, and deploy any ML model. And, that process will be progressive and iterative. Beware of getting locked into tooling or workforce contracts. If there’s one thing that’s certain in ML development, there will be technical changes, learning, and plenty of surprises along the way.
Make sure your tooling, workforce, and process provide the flexibility and agility you need to innovate. In general, you’ll want to think big, start small, and scale fast. Your choices are likely to make the difference between winning or losing your race to market.
(Originally published by AltexSoft)