Companies in the autonomous vehicle (AV) industry strive for safe, cost-effective AV models in various ways. But have you ever considered an AV data pipeline supported by superior-quality training data, especially for edge cases, as a path to safety? Read on. We'll show you how.
Because you’re in the AV industry, you’ve likely seen these statistics—or others like them:
- A study by the University of Michigan found that autonomous vehicles get into 9.1 crashes per million miles driven compared with 4.1 crashes per million miles for conventional vehicles. (The study is from 2015, but the statistic lives on.)
- Between July 2021 and May 2022, autonomous vehicle (AV) companies reported 367 Level 2 ADAS crashes to the National Highway Traffic Safety Administration.
- To demonstrate enough safety and reliability to release autonomous vehicles (AV) into the world, developers of AV technology have to drive for hundreds of millions or even hundreds of billions of miles—an impossible task without using modeled simulations.
Statistics like those, plus ongoing media coverage of high-profile autonomous vehicle crashes—such as the Tesla that crashed at 100 mph into a large pile of rocks—keep the public wary of the safety of autonomous vehicles.
And according to Morning Consult, public sentiment has actually slipped since early 2018, when 27% of respondents said self-driving vehicles were safer than regular vehicles. In early March 2022, only 19% of respondents shared that sentiment.
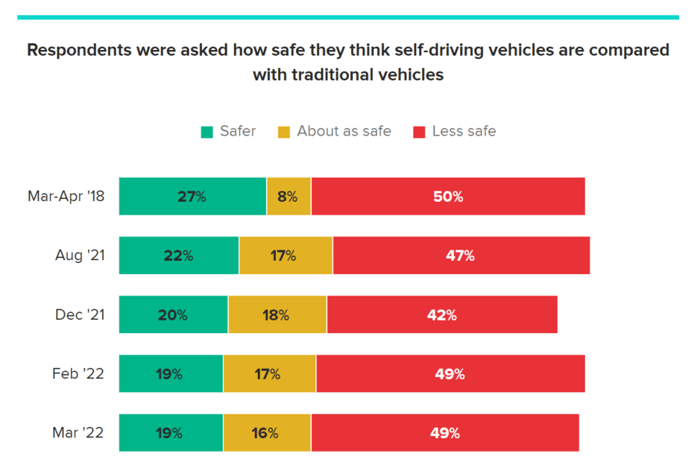
Source: Morning Consult
Because you’re a member of the autonomous vehicle industry, we know you take safety seriously.
Perhaps you participate in the AV TEST Initiative, the tracking tool developed by the National Highway Traffic Safety Administration (NHTSA) that lets the public know what your organization is doing to ensure safe autonomous vehicles.
Maybe you take a holistic approach to safety by infusing safety into your organizational culture. Or perhaps you maintain a safety case framework or use a safety management system.
Another road to developing safe AV models is a strong AV data pipeline supported by superior-quality training data. This is especially important for edge cases because they prepare your AI models for what happens after they encounter the unexpected, such as a jaywalker or a distracted driver running a stop sign.
Creating such a pipeline takes three steps:
- Design and build.
- Deploy and operationalize.
- Refine and optimize.
Let’s look at each.
-
Design and build
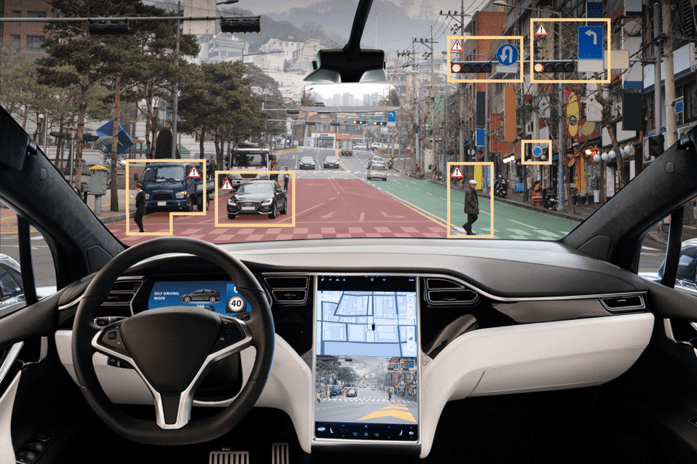
Think about design and build as the proof of concept phase. Here, your AV team determines what data they already have, what data they need to acquire, and how to use high-quality labels to turn that raw data into training data.
AV data operations are a lot like the assembly lines of yesteryear’s industrial factories, except data is the raw material that travels through multiple processing and review steps to prepare it for execution.
During the design and build phase, you aim to create a safe working model by acquiring and labeling minimal amounts of data from various sensors, including LiDAR, radar, GPS, electrocardiogram (ECG), sonar, cameras, and vehicle to everything (V2X) systems inside and outside the vehicle.
When you decide your model works safely and is worth putting into production, you move on to the deploy and operationalize stage, where you feed mountains of high-quality data, including data related to critical edge cases, into the training model.
-
Deploy and operationalize

Proper data management is crucial during the deploy and operationalize phase to avoid model weaknesses or failures. This is where most failures occur, and it is only to be expected. In fact, 96% of failures occur during and after this phase, hence the need for ongoing testing and refinement.
Because issues with data quality can mean costly setbacks for your AV technology, quality control is critical for ensuring the model is safe and ready for use in real-world situations.
In autonomous driving, the volume and quality of data will directly affect your model’s performance, so the amount of data you need will continue to soar.
Autonomous driving machine learning models can grind to a halt when trained on inadequate, inaccurate, or irrelevant data in the early stages, making a longstanding premise painfully true: Garbage in, garbage out.
In a deliberate effort to avoid model failures, AV teams commonly rely on managed workforces specializing in data annotation and QA during this phase of the AV data pipeline.
Even if you use automation to apply labels, a managed, human-in-the-loop (HITL) workforce offers a unique understanding of edge cases—an understanding vitally important for model accuracy to ensure safety.
Just as the Lamborghini Aventador S uses premium, high-octane fuel to power its engine, an AV data pipeline thrives on premium data to power its models. The Lamborghini won’t run on low-quality fuel; your autonomous driving model won’t run on low-quality data.
You’re not creating average technology, so don’t settle for average data.
-
Refine and optimize
The ongoing refine and optimize stage occurs after a model is minimally and safely deployed in a test city or simulation environment or enters mass production. As major edge cases emerge or as you expand innovation, your AV team loops back to the start of the data pipeline to train a new model or considerably enhance—sustain—an existing model.
As long as you can regularly obtain and prepare new AV training data, your team can monitor the model’s performance over time, determining when a new model or an update is necessary. If your model’s accuracy noticeably degrades, it’s time to retrain with fresh data. A degraded AV model is fruitless. And the cost of errors can be huge—to you and to society.
Although this stage of the AV data pipeline ultimately improves the safety of AV models, it can be a drag for your in-house AV team because refinement and optimization continually loop. And it can take hundreds of people using advanced tooling software to refine the data. When this happens, your AV team may want to join forces with an AV-centric external workforce to produce a groundbreaking—and safe—AV model.
What’s next for you in terms of AV model safety?
To maximize safety with quality outputs at scale and learn more about the multiple workforce approach for training and sustaining your AV models, download our ebook: Optimizing Data Pipeline Using Multiple Workforces: An Ebook for Autonomous Vehicle Technology Professionals.
