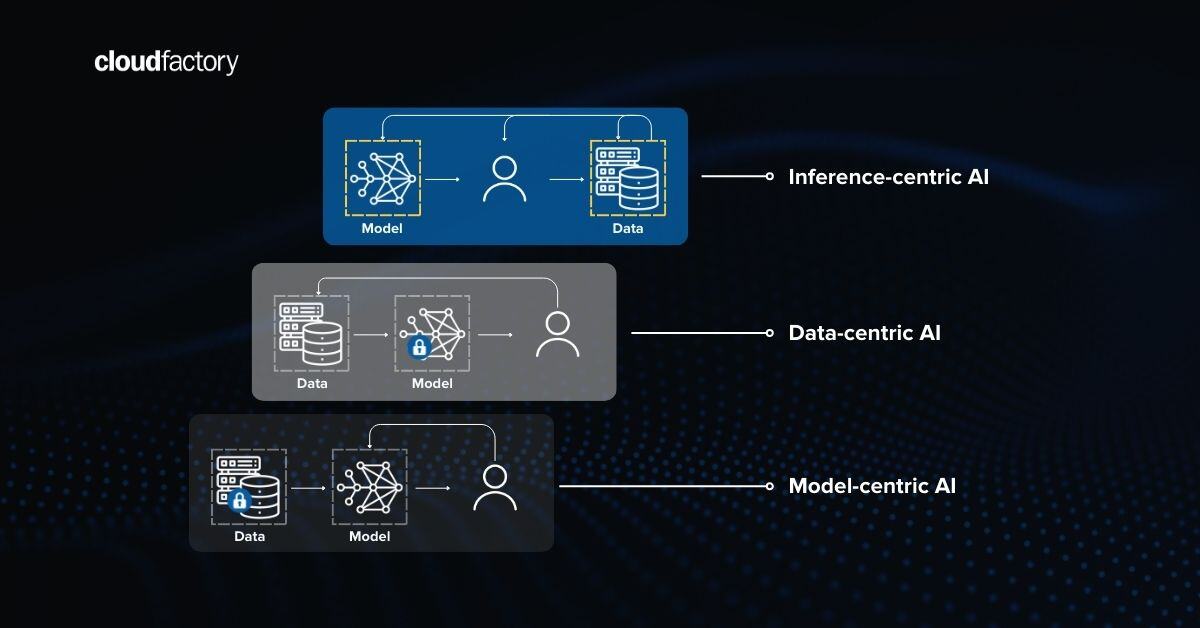
Maslow's hierarchy of needs is a theory that suggests that humans are motivated to fulfill five basic needs in order to reach their full potential.
According to Maslow, we cannot move on to the next level of needs until the previous level is met. For example, if we're not getting enough food, we won't be able to focus on our safety needs.
If we don't have a strong foundation of basic needs met, it can lead to negative consequences, such as stress, anxiety, and depression.
However, if we're able to meet our basic needs, we're more likely to be able to reach our full potential and live a happy and fulfilling life.
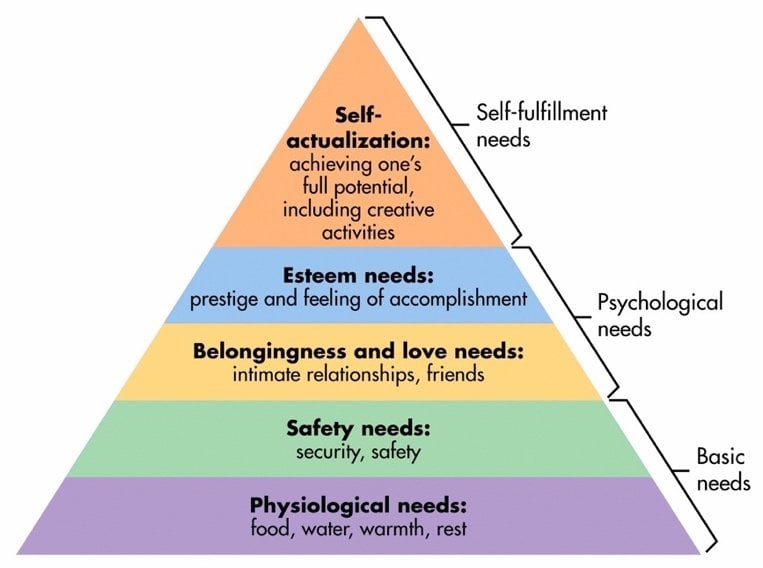
Maslow's hierarchy of needs is a theory that arranges human needs into a hierarchical structure, progressing from basic physiological requirements to higher-level psychological and self-fulfillment needs.
In this blog post, we will use Maslow's hierarchy of needs to illustrate how business leaders can build a machine learning (ML) solution foundation. We believe that this comparison will make the ML model-building process easier to understand.
After reading this post, we encourage you to check out our accompanying blog post that explores how technical leaders can build an ML model-building process using Maslow's hierarchy of needs as a framework.
The graphic below illustrates the different stages of Maslow's hierarchy of needs in the context of building an ML solution foundation for business leaders:
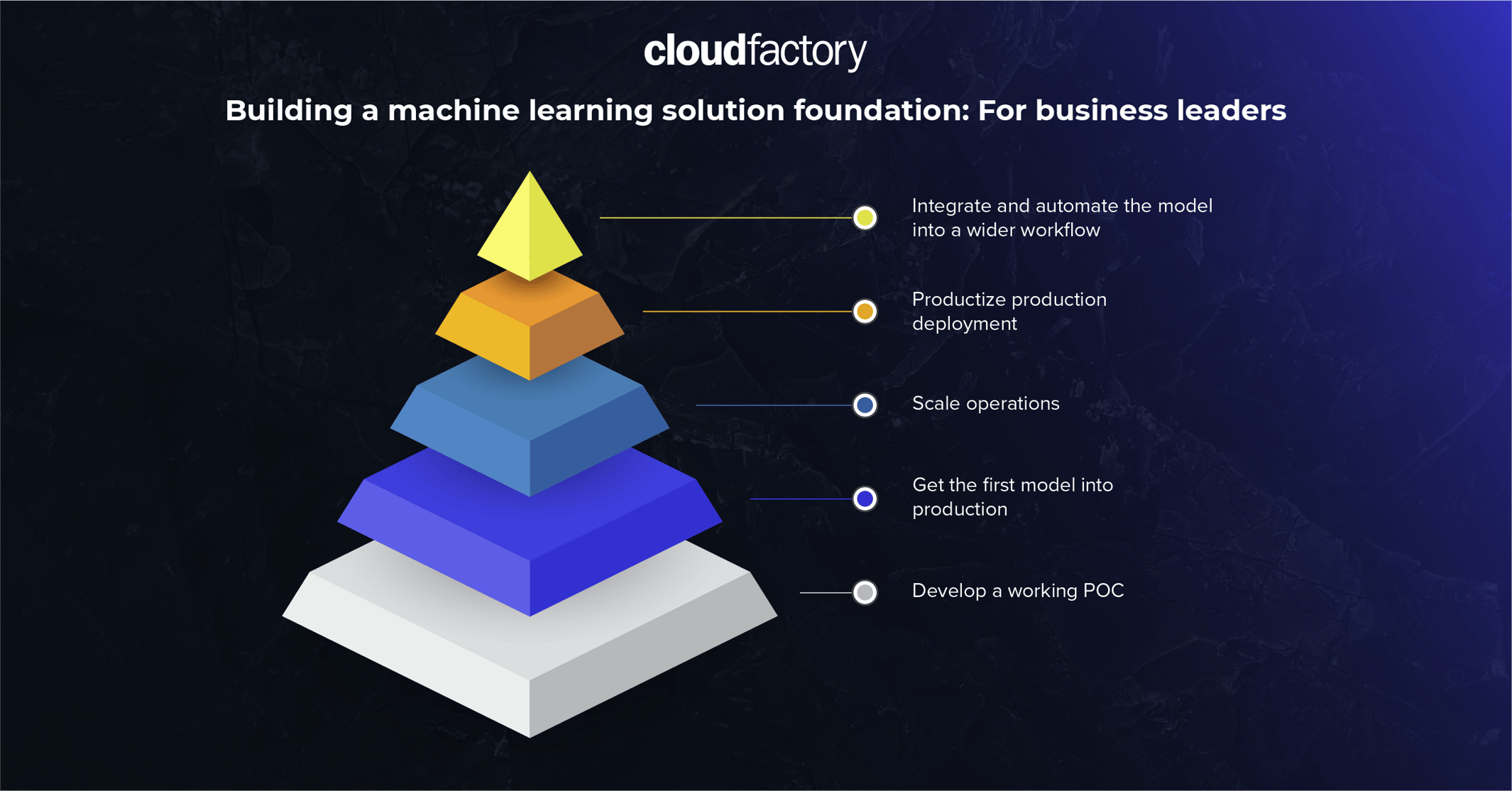
1. Develop a working POC (Proof of Concept)
Look before jumping.
Machine learning (ML) can be a powerful tool for businesses, but it's important to take a step back and plan before you start integrating a new ML model into your operations. Here's why:
Your initial hypotheses may not be correct. When you're first starting out with ML, you may have a lot of assumptions about what will work and what won't. But, as you start to collect data and train your model, you may find that your initial assumptions were wrong.
Often, the hypotheses you make in the beginning might not turn viable in the end. Here are just a couple of examples:
- Architecture choice: You might learn that a different architecture is more suitable for your task. For example, you might decide to use a simple convolutional network, but find out that more modern transformer networks might be a better choice. Or, you decide to use transformers but find out that your task can be accomplished using a simple CNN network.
- Dataset quality: It's important to analyze your dataset closely. Issues like inadequate size for accurate model generalization, data annotation errors, lack of diversity, or biases might emerge. For instance, when labeling cars, if you notice that most have a person inside, and the model wrongly sees this as a key feature for car detection, it can lead to significant errors.
- Expertise Gap: Occasionally, your team's skillset may fall short of your objectives, necessitating skill upgrades (e.g., mastering new frameworks/platforms) or bringing in external specialists. Having a domain expert onboard ensures you stay current and grasp advancements in your pursuit.
- Feasibility check: Even if your team is skilled at execution, the process might prove more expensive and time-intensive than anticipated. For instance, businesses often invest months in gathering high-quality datasets and compensating specialized annotators. Ask yourself:
• Do your resources align with solution development?
• Can you weather this non-profitable development phase?
These are critical questions. Initial estimates may suggest a $10,000, 3-month plan, but unforeseen needs—extra equipment, server resources, and domain experts—could escalate projections to $100,000.
Key takeaway: Tweaking things early is less expensive than later. Ultimately, you might realize an AI solution isn't essential or that it requires more resources than you can manage. This is why creating a POC is the base of our foundation.
2. Get the first model into production
It's the moment of truth.
After developing a first POC, you'll want to develop your first real-world prototype by following these steps:
- Start with a prototype. Don't try to build a perfect, fully-featured model right away. Start with a small, well-functioning prototype that you can test with real users.
- Gather feedback from users. Once you have a prototype, get feedback from real users to see how they're using it and what they like and don't like. This feedback will make sure that the ML model is meeting their needs and providing value to your business.
Here are some specific ways to get feedback from users:
- Surveys: Surveys are a great way to get feedback from a large number of users. You can ask questions about their experience with your model, their preferences, and what features they would like to see.
- Interviews: Interviews are a more in-depth way to get feedback from users. You can ask them about their specific needs and how your model can be improved to meet those needs.
- User testing: User testing is a great way to see how users interact with your model in real-time. You can observe them as they use the model and get feedback on their experience.
- Iterate and improve. Continue to iterate on your model based on user feedback. This is an ongoing process, as you'll always be learning and improving your model.
Next, here are some "in the weeds" tips for getting your first ML model into production:
- Use a cloud-based platform. This will make it easier to deploy and scale your model.
- Use a managed ML service. This will take care of the heavy lifting of managing your model so you can focus on building and improving it.
- Use a continuous integration and deployment (CI/CD) pipeline. This will automate the process of deploying your model to production so you can release new versions more quickly.
- Monitor your model's performance. Once your model is in production, you need to monitor its performance to make sure it's working as expected.
Key takeaway: Getting your first ML model into production is an iterative process that requires continuous feedback and improvement. By following these tips, you can increase your chances of success.
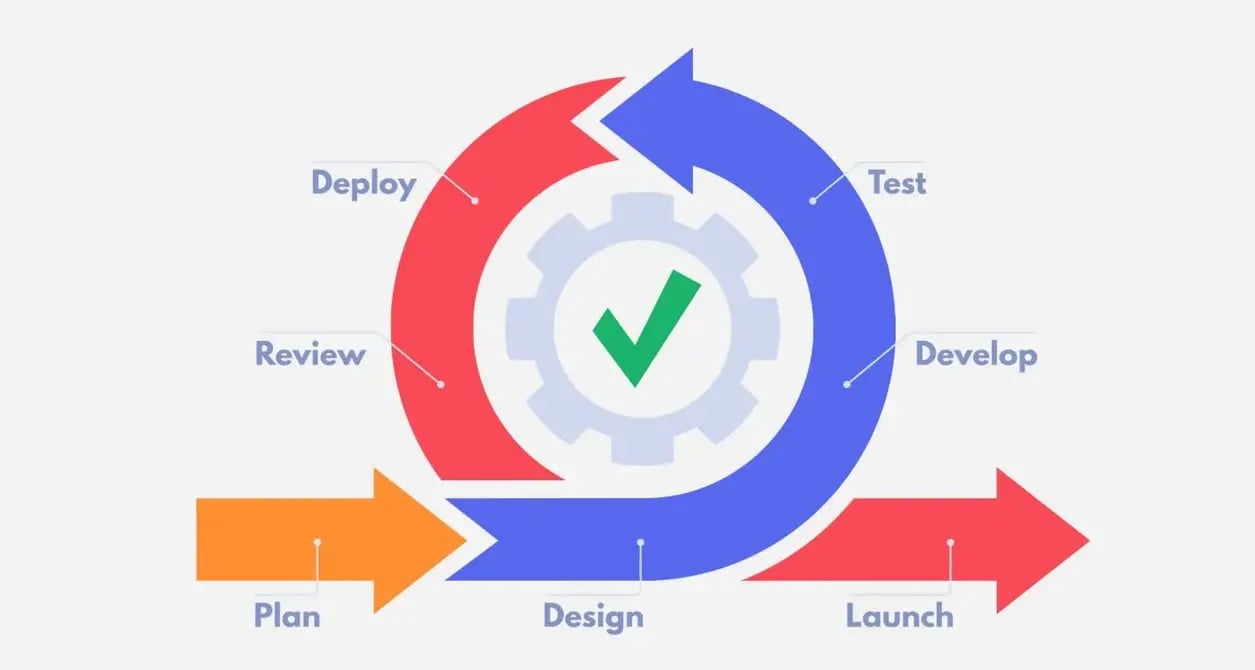
Iterative development is the process of working in repeated cycles. Source: Plume.co.uk.
For example, this could be going through a cycle of building a specification for features and functionalities, designing, feature development, and then testing.
3. Scale operations
It's time for the "S" word.
Your prototype is working. Your consumer base is continuing to grow. The load on your servers is increasing, and it's time to think about scaling.
There are two ways to scale your product:
- Vertical scaling: AKA scaling up
- Horizontal scaling: AKA scaling out
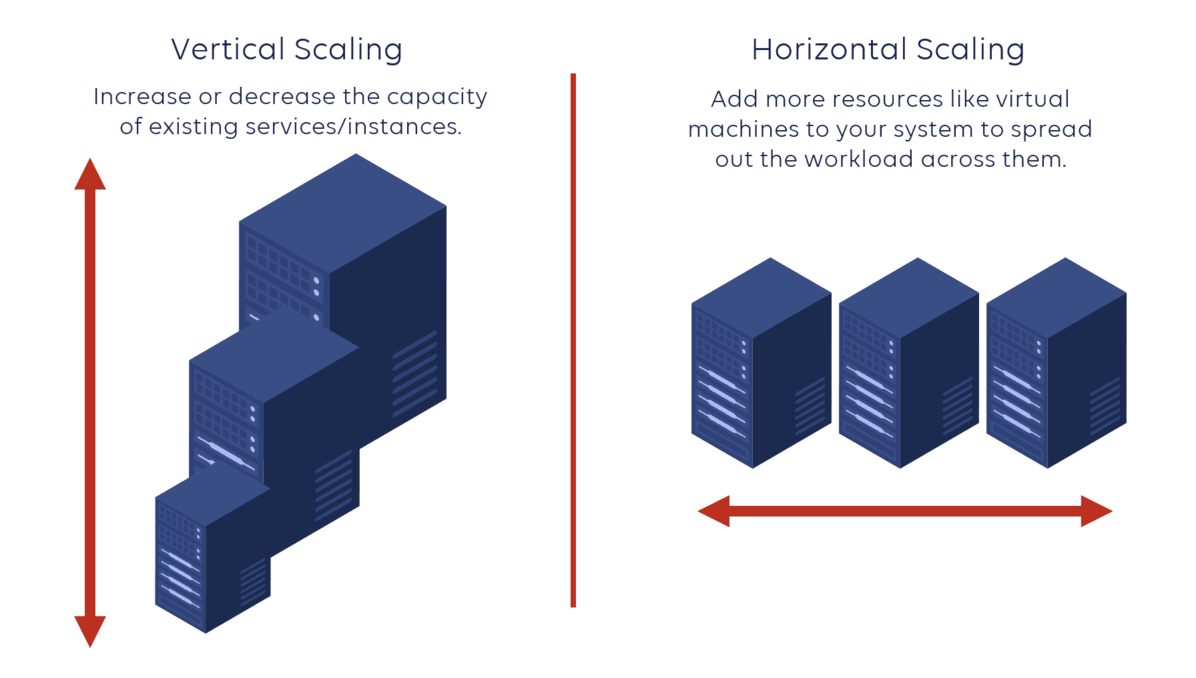
Horizontal scaling is a long-term cloud scalability solution that adds more servers to the infrastructure, while vertical scaling is a short-term solution that adds more resources to existing servers. Source: StormIT.
Vertical Scaling (VS) is the simplest option. If your server cannot handle the load optimally anymore, then you can upgrade it by inserting more RAM, better GPUs, and CPUs. This does not require almost any change in your codebase.
Despite its simplicity, this method has some major limitations. Imagine that your system is struggling to handle user requests, so you insert a better CPU and increase the amount of RAM. This solves the problem until your client base and the load increase again. Someday you might end up reaching the top limit of how much you can squeeze out of your system.
In that case, you would have to turn to Horizontal Scaling.
Horizontal Scaling (HS) is another method of handling the load. Instead of adding more resources into a single system, you can add other systems that can split the load between each other.
HS has some great benefits:
- You can distribute servers worldwide to improve the response time for different users. If most of your consumers are from the United States, but your servers are in Germany, then having the server as close to them as possible will improve the response times, resulting in customer satisfaction.
- You can do load balancing. Some of your servers are experiencing a high load. You can redirect some load to other servers.
- HS scaling is rather fail-proof. When you have a single system, if something happens to it, then your whole business is down until you fix it. The potential loss of information and user data might cost you a lot of trouble and customers. But if you have multiple servers, then if one fails, you can redirect its requests to the closest servers.
However, in order to implement horizontal scaling, your codebase should support it. If your codebase does not support horizontal scalability from the start, it will cost a lot of time and resources to rebuild it and make it separable to distribute the load between different systems.
At CloudFactory, we take the scaling challenge to our heart. Therefore, the technical team behind the CloudFactory’s annotation tool has developed a semi-automated Inference Engine. Our Inference Engine brings powerful ML solution monitoring capabilities along with scaling options that are adjustable based on the current workload and needs.
Key takeaway: When your product is growing, and the load on your servers is increasing, you need to think about scaling. There are two ways to scale your product: vertical scaling and horizontal scaling. Vertical scaling is the simplest option, but it has limitations. Horizontal scaling is more complex to implement, but it has many benefits, such as improved response time, load balancing, and fault tolerance.
4. Productize production deployment
You've hit the big time.
You've been fixing and adding functionality to your product for some time. Now, it's time to productize it.
In this step, you transform your prototype or POC into a product that is ready for commercial use.
How is that different from what you already have? Several aspects should be considered and refined when you prepare the product for production. These steps include, but are not limited to:
- Security - Prioritize security by conducting basic checks and addressing vulnerabilities. As your customer base grows, you become a target for various third parties seeking to exploit weaknesses or access user data for unauthorized purposes. Security matters greatly to end users. No one wants their information leaked or accessed without permission, even if it's not personal data.
- User experience - Your product should be well-documented and easy to use. Doing this ensures that as many people as possible can use your product and increase your consumer base. Also, it is one of the most noticeable factors in choosing between competitors. If two solutions provide similar functionality, but one is easier to use, then the choice is obvious.
- Support - Listening to user feedback and keeping an eye on your product for issues or ways to make it better is crucial. Plus, with new tech and software coming out all the time in IT, being the first to use and offer them could give you an edge against rivals.
- Distribution and monetization: Naturally, you'll need to determine how your product will generate revenue. Will you opt for a paid model or provide it for free? Are subscriptions or ad revenue part of your strategy? This topic warrants dedicated attention and a significant amount of time to develop effectively.
Key takeaway: When you're ready to productize your ML model, you need to focus on security, user experience, support, distribution, and monetization. By addressing these factors, you can ensure your product’s success in the commercial market.
5. Integrate and automate the model into a wider workflow
You did it.
Your model is successfully serving your clients. Now, it's wise to explore ways of smoothly integrating your model into a broader business workflow. This might entail refining your existing operations or seamlessly incorporating the model into an entirely new business process. Here are two approaches to achieve this:
Monitoring model predictions: When dealing with dynamic data like prices, weather, or real-time user interactions, keeping track of how your model makes predictions becomes crucial. As your model grows, you'll encounter various unique cases and room for enhancements. Yet, manually inspecting every prediction can become time-intensive.
This is where the data flywheel approach comes in handy. This approach integrates the machine learning model development into an ongoing improvement cycle. Because real-world data will naturally differ from the initial training data (known as the data shift problem), it's vital to ensure your model continuously learns from new data and adjusts its predictions based on feedback from its surroundings.
Maximizing your asset's value through integration: Another effective approach is embedding your asset into new solutions. If you're crafting a solution that aligns with your asset's capabilities, using it instead of creating a new model can save time and resources.
Imagine a model that adds color to images of people. When expanding to support various grayscale images, employing your existing model can save time and effort. For success, ensure your model is separate from your current solution and integrates seamlessly. Your workflow should independently communicate with the model for input and output.
Taking it further, envision a solution where your model plays a supporting role, not directly accessed by end users. For instance, transforming grayscale videos into color could leverage your existing model to process frames individually.
Key takeaway: Once your machine learning model is successful, you need to integrate it into your business workflow and automate it as much as possible. This will help you to maximize the value of your model and improve your business processes.
CloudFactory understands the building blocks of the ML hierarchy.
CloudFactory has been helping ML teams for 10+ years, and we know what it takes to build solid ML foundations that lead to successful ML models that will ultimately increase revenue.
With our managed team approach, you'll have a dedicated team of experts working with you to ensure the success of your project. We'll reduce the expense and time burden of hiring and managing an internal team or generic service provider.
CloudFactory helps you every step of the way, from data labeling to model training and deployment. We'll work with you to understand your business goals and develop a solution that meets your specific needs no matter which hierarchy of need level your organization is on.